All the Different Types of Tests You Can Run on Your Site (+ When to Run Them)
The experimentation world has mostly moved beyond simple button color A/B tests.
They may have their place in the portfolio of experiments you’re running, but hopefully, at this point, they’re not synonymous with experimentation or CRO.
Experimentation can be so much bigger.
Using different types of experiments, we can learn about the variance on our websites, test novel experiences, uncover new page paths, make big leaps or small steps, and identify the optimal combination of elements on a page.
What you hope to learn from an experiment should be reflected in its design, and the design of experiments goes well beyond simply testing A versus B using a concrete hypothesis.
In fact, there’s a whole subfield of study known as design of experiments (DoE) that covers this.
Design of Experiments: an Introduction to Experimental Design
Design of Experiments (DoE) is a scientific method used to determine the relationship between factors affecting a process and the output of that process.
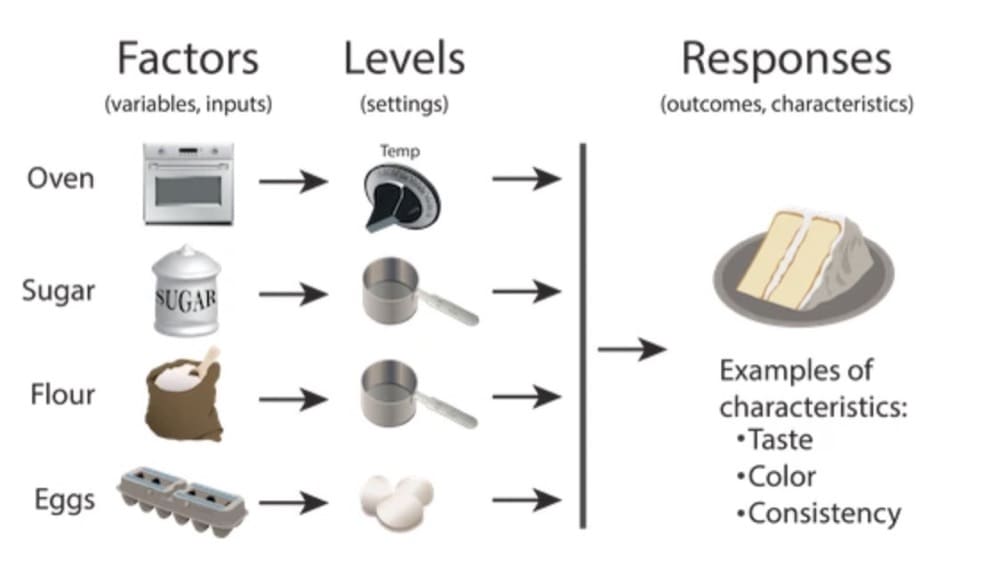
Design of Experiments is a concept popularized by statistician Ron Fisher in the 1920s and 1930s.
DoE allows us to understand how different input variables affect a process output by systematically changing the inputs and observing the resulting changes in the output. This approach can be used to optimize a process, develop new products or features, or learn which elements work best in conjunction with each other.
In marketing, we use DoE to improve our understanding of how different elements on a page (the factors) affect conversion rates (the output). By designing experiments effectively, we can identify which elements have the biggest impact on conversion rates.
There are many different types of experiments, and each type can be used to learn different things about your website or app.
In this article, I’ll cover 16 types of experiments.
Nitpickers might note that these are not all fundamentally different experimental designs; rather, some are different “types” because of how you generate your hypothesis or what frameworks underlie your reasons for running the experiment.
Some, additionally, aren’t quite “experiments,” but are rather optimization rules built on machine learning models.
Still, each of the following has a distinct purpose and can be looked at as a unique tool in the toolkit of an experimenter.
16 Common Types of Experiments
There are many different types of controlled experiments you can run on your website, but here are 16 of the most common ones:
1. A/A test
2. Simple A/B test
3. A/B/n test
4. Multivariate test
5. Targeting test
6. Bandit test
7. Evolutionary algorithms
8. Split page path test
9. Existence test
10. Painted door test
11. Discovery test
12. Incremental test
13. Innovative test
14. Non-inferiority test
15. Feature flag
16. Quasi experiments
1. A/A Test

An A/A test is a simple concept: you’re testing two versions of a page that are identical.
Why would you do this?
There are a bunch of reasons, mainly in pursuit of calibration and understanding the underlying data, user behavior, and randomization mechanisms of your testing tool. A/A testing can help you:
- Determine the level of variance in your data
- Identify sampling errors within your testing tool
- Establish baseline conversion rates and data patterns.
Running A/A tests is weirdly controversial. Some swear by it. Some say it’s a waste of time.
My take? It’s probably worth running one at least once, for all the aforementioned reasons. Another reason I LOVE to run A/A tests is to explain statistics to testing newbies.
When you show someone a “significant” experiment with two days of data collected, only to later reveal it was an A/A test, then stakeholders usually understand why you should run an experiment to completion.
If you want to read more about A/A testing (it’s a huge subject, actually), Convert has an in-depth guide on them.
Use cases: calibration and determining data variance, auditing experimentation platform bugs, determining baseline conversion rate and sample requirements.
2. Simple A/B Test

Everyone knows what a simple A/B test is: you’re testing two versions of a page, one with a change and one without.
A/B tests are the bread and butter of experimentation. They’re simple to set up and easy to understand, but they can also be used to test big changes.
A/B tests are most commonly used to test changes on a user interface, and the goal of a simple A/B test is almost always to improve the conversion rate on a given page.
Conversion rate, by the way, is a generic metric that covers all sorts of proportions, such as the activation rate of new product users, monetization rates of freemium users, lead conversion rates on the website, and click-through rates.
With a simple A/B test, you have a singular hypothesis and change one element at a time in order to learn as much as you can about the causal elements of your change. This could be something like a headline change, button color or size change, adding or removing a video, or really anything.

When we say “A/B test,” we’re mostly using a generic term to encompass most of the rest of the experiment types I’ll list in this post. It’s usually used as an umbrella term to mean, “we changed *something* – large, small, or many elements – in order to improve a metric.”
Use cases: Many! Usually to test a singular change to a digital experience informed by a concrete hypothesis. A/B tests are typically run with the intent to improve a metric, but also to learn about any change that occurs in user behavior with the intervention. Take a look at these A/B testing examples for inspiration.
3. A/B/n Test

A/B/n tests are very similar to A/B tests, but instead of testing two versions of a page, you’re testing multiple versions.
A/B/n tests are similar, in some ways, to multivariate tests (which I’ll explore next). Rather than a “multivariate” test, however, I’d consider these a multi-variant test.
Multivariate tests are useful for understanding the relationships between different elements on a page. For example, if you want to test different headlines, images, and descriptions on a product page, and you also want to see which combinations seem to interact best, you would use a multivariate test.
A/B/n tests are useful for testing multiple versions of a single element and don’t care as much about interaction effects between elements.
For example, if you want to test three different headlines on a landing page, you would use an A/B/n test. Or, you could just test seven completely different versions of the page. It’s just an A/B test with more than two experiences tested.
A/B/n tests are solid choices when you’ve got a lot of traffic and want to test several variants efficiently. Of course, the statistics need to be corrected for multiple variants. There’s also a lot of debate around how many variants one should include in an A/B/n test.
Often, you can push some more original and creative variants when testing several experiences at once as opposed to iteratively across multiple simple A/B tests.
Use case: when you have the available traffic, multiple variants are great to test a wide-ranging assortment of experiences or multiple iterations of an element.
4. Multivariate Test

A multivariate test is an experiment with multiple changes. Where an A/B/n test is testing the composite versions of each variant against each other variant, a multivariate test also aims to determine the interaction effects among the elements tested.
Imagine, for example, that you’re redesigning a homepage. You’ve done conversion research and have uncovered clarity issues with your headline, but you’ve also got some hypotheses around the level of contrast and clarity in your CTA.
Not only are you interested in improving each of those two elements in isolation, but the performance of these elements is also likely dependent. Therefore, you want to see which combination of new headlines and CTAs works best.
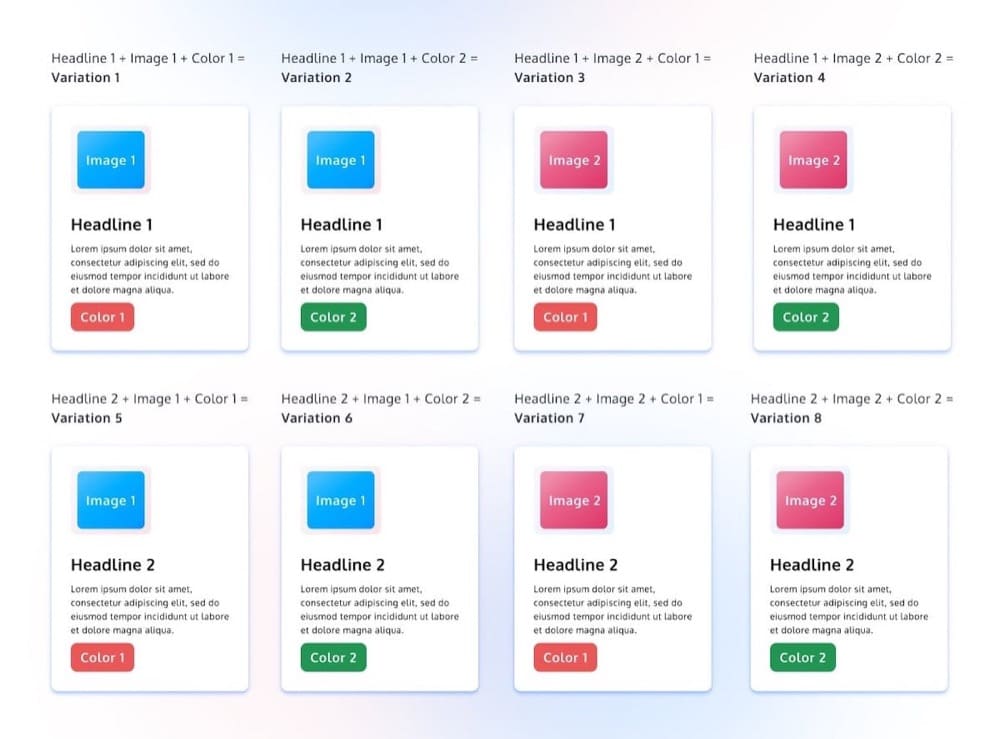
Experiment design gets a lot more complicated when you enter multivariate territory. There are a few different types of multivariate experiment setups, including full factorial design, partial or fraction factorial design, and Taguchi testing.
And just as a matter of statistical common sense, multivariate tests almost certainly require more traffic than simple A/B tests. Each additional element or experience you change increases the amount of traffic you need for a valid result.
Use cases: multivariate experiments seem particularly beneficial for optimizing an experience by tweaking several small variables. Whenever you want to determine the optimal combination of elements, multivariate tests should be considered.
5. Targeting Test
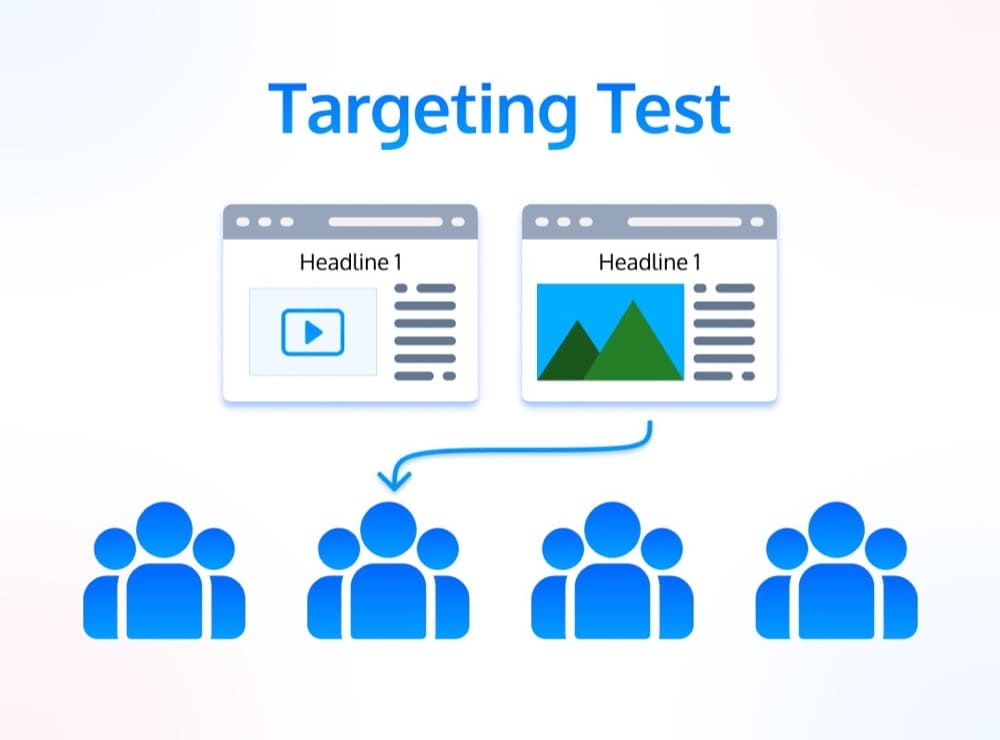
Targeting tests, better known as personalization, are all about showing the right message to the right person at the right time.
With a targeting test, you can create different versions of a page and show each version to a different group of people. The goal is usually to increase conversion rates by showing relevant content to each user.
Note that personalization and experimentation aren’t synonyms. You can personalize an experience without treating it as an experiment. For example, you can decide with zero data or intent to collect data, that you’ll use a first name token in your emails to personalize messages with the recipient’s name.
Personalization? Yes. Experimentation? No.
But you can also run experiments targeting specific segments of users. This is especially common in product experimentation, where you can isolate cohorts based on their pricing tier, signup time, signup source, etc.
The same statistics apply to personalization experiments, so it’s important to choose meaningful segments to target. If you get too granular – say targeting rural Kansas mobile Chrome users who have between 5 and 6 sessions – not only will it be impossible to quantify the impact statistically, but it’s unlikely to be a meaningful business impact as well.
Personalization is typically looked at as a natural extension of simple A/B testing, but in many ways, it introduces a ton of new complexity. For each new personalization rule you employ, that’s a new “universe” you’ve created for your users to manage, update, and optimize.
Predictive personalization tools help you identify target segments as well as experiences that seem to work better with them. Otherwise, personalization rules are often identified by doing post-test segmentation.
Use cases: isolate treatments to specific segments of your user base.
6. Bandit Test

A bandit test, or using bandit algorithms, is a bit technical. But basically they differ from A/B tests because they’re constantly learning and changing which variant is shown to users.
A/B tests are typically “fixed horizon” experiments (with the technical caveat of using sequential testing), meaning you predetermine a trial period when you’re running the test. Upon completion, you make a decision to either roll out the new variant or revert to the original.
Bandit tests are dynamic. They constantly update the allocation of traffic to each variant based on its performance.
The theory goes like this: you walk into a casino and stumble upon several slot machines (multi-armed bandits). Assuming each machine has different rewards, the bandit problem helps “decide which machines to play, how many times to play each machine and in which order to play them, and whether to continue with the current machine or try a different machine.”
The decision process here is broken down into “exploration,” wherein you try to collect data and information, and “exploitation,” which capitalizes on that knowledge to produce above average rewards.
So a bandit test on a website would seek to find, in real time, the optimal variant, and send more traffic to that variant.
Use cases: short experiments with high “perishability” (meaning the learnings from the results won’t extend very far into the future), and longer term “set it and forget it” dynamic optimization.
7. Evolutionary Algorithms
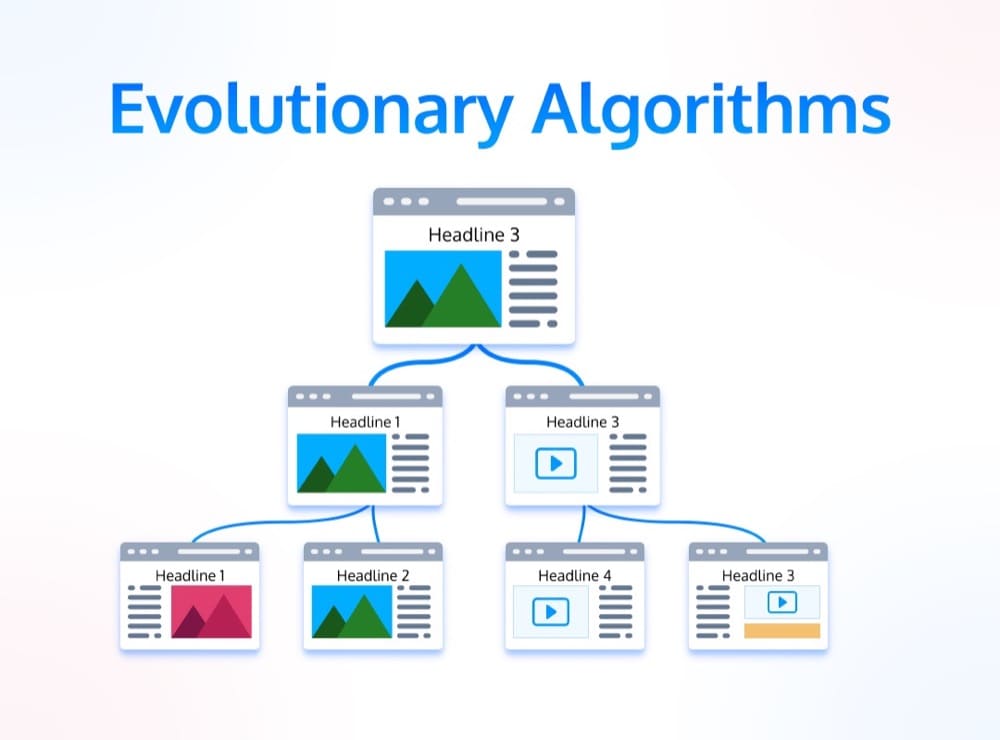
Evolutionary algorithms are sort of a combination between multivariate tests and bandit tests. In the context of marketing experiments, evolutionary algorithms allow you to test a large number of variants at the same time.
The goal of an evolutionary algorithm is to find the optimal combination of elements on a page. They work by creating a “population” of variants and then testing them all against each other. The best-performing variant is then used as the starting point for the next generation.
As suggested by the name, it uses evolutionary iterations as a model for optimization. You have a ton of different versions of headlines, buttons, body copy, and videos, and you splice each of them together to create new mutations, and dynamically try to kill off weak variants and send more traffic to strong variants.
It’s like multivariate testing on steroids, albeit with less transparency in interaction effects (thus, a lower learning potential).
These experiments also require quite a bit of website traffic to work well.
Use cases: massive multivariate testing, splicing together several versions of creative and finding the emergent winner among all the combinations.
8. Split Page Path Test
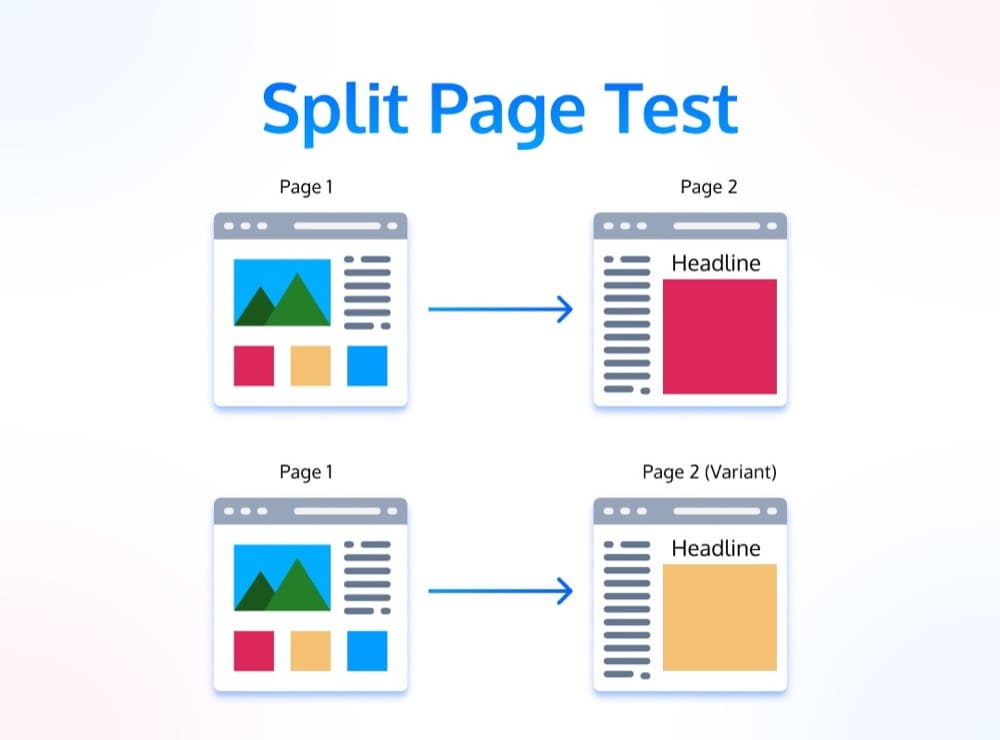
A split page path test is also a very common type of A/B testing.
Instead of changing an element on a single page, you’re changing the entire path that a user takes through your website.
With a split page path test, you’re essentially testing two different versions of your website, product, or funnel. The goal is usually to find the version that results in more conversions or sales. It can also help identify dropoff points in the funnel, which can diagnose focus areas for further optimization.
Basically, instead of changing the copy on a button, you change the next page that buttons sends you to if you click on it. It’s a powerful way to experiment with the customer journey.
Use cases: identify and improve page paths and user funnels in a product or on a website.
9. Existence Test

Existence testing is an interesting concept. What you’re trying to do is quantify the impact (or lack thereof) of a given element in your product or website.
According to a CXL article, “Simply put, we remove elements of your site and see what happens to your conversion rate.”
In other words, you’re testing to see if a change has any effect at all.
Strategically, this is such an underrated strategy. We often assume, either through our own heuristics or through qualitative research, which elements are the most important on a page.
Surely, the product demo video is important. Existence testing is a way to question that belief and quickly get an answer.
You just remove the video and see what happens.
Conversion rate increase or decrease? Interesting – that means the element or real estate it occupied is impactful in some way.
No impact? That’s interesting too. In that case, I’d point my team’s focus on other parts of the digital experience, knowing that even removing the element entirely does nothing to our KPIs.
Use cases: “Conversion signal mapping.” Essentially, this can tell you the elasticity of elements on your website, AKA do they even matter enough to focus your optimization efforts on?
10. Painted Door Test

A painted door test is similar to an existence test in a way. They’re very common for testing new offers as well as testing out the demand for new product features.
Basically, a painted door test is an experiment to see if people will actually use a new feature or not. You don’t actually spend the time and resources to *create* the new offer or feature. Rather, you create a “painted door” to see if people walking by will even try to open it (i.e. you create a button or landing page and see if people even click it, inferring interest).
The goal of a painted door test is to find out if there is any demand for the thing you’re testing. If people are actually using the new feature, then you know it’s worth pursuing. If not, then you know it’s not worth your time and can scrap the idea.
They’re also known as smoke tests.
Painted door tests are a great way to test new ideas without investing a lot of time or money.
Because you don’t actually have an offer or experience creating, you can’t usually use KPIs like conversion rate. Rather, you have to model out your minimum threshold of expected value. For instance, creating X feature will cost Y, so given our existing baseline data, we’ll need to see Y click-through-rate to warrant creating the “real” experience.
A pre-launch waiting list is, in some ways, a painted door test (with the famous example being Harry’s razors).
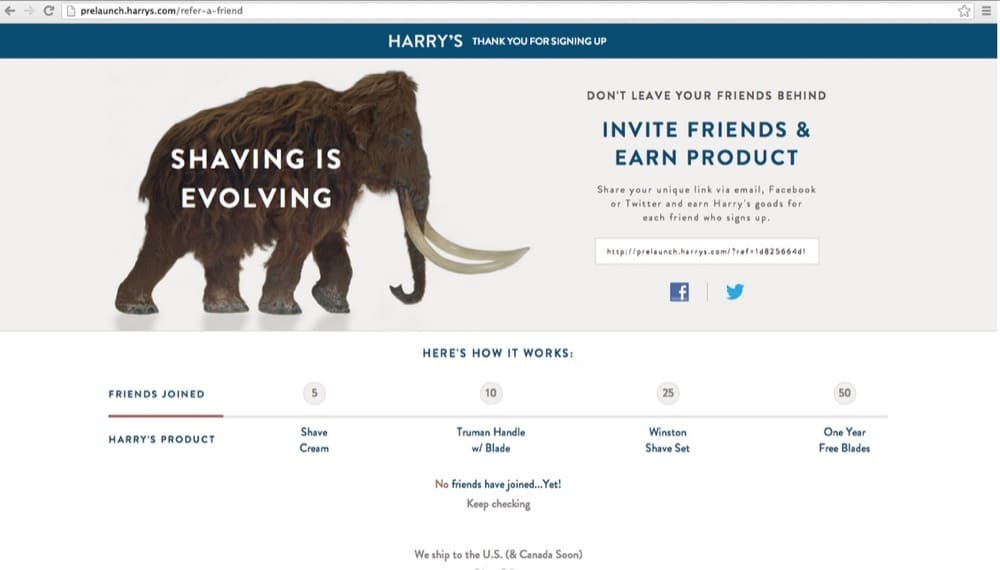
Use cases: prove out the business case for investing time and resources into creating a new feature, offer, or experience.
11. Discovery Test

Discovery tests, which I pulled from Andrew Anderson’s Discipline-Based Testing Methodology, are all about increasing the range of possible options.
They’re almost always a version of A/B/n tests with multiple variants, but they don’t necessarily have to be designed that way. The larger purpose of these is to test options outside the range of what you would normally have considered reasonable. This mitigates your own bias, which can limit the scope of options you ever consider.
Instead of narrowly defining a hypothesis, you’re hoping to get outside of your own biases and potentially learn something completely novel about what works with your audience.
To do a discovery test, you take a piece of real estate on your product or website and generate a bunch of different variants. The goal is each variant is quite different from the last, giving you a wide range of dissimilar options. The goal is to find something that works, even if you don’t know what it is ahead of time.
In discovery tests, it’s important to map your experiment to your macro-KPI and not optimize for micro-conversions. It’s also important to test on meaningful and high traffic experiences, since you’ll want appropriate statistical power to uncover lifts among the many variants.
To see an example of an experiment like this, check out Andrew Anderson’s example from Malwarebytes where they tested 11 vastly different variants.
Use cases: de-constrain your experimentation efforts from biased hypotheses and find outside the box solutions that, while they may go against your intuition, ultimately drive business results.
12. Iterative Test

There’s a concept known in computer science as the “hill climbing problem.” Basically, hill climbing algorithms seek to find the highest point in a landscape by starting at the bottom and constantly moving up.
The same concept can be applied to marketing experiments.
With an iterative test, you start with a small change and then keep making it bigger until you reach the point of diminishing returns. This point of diminishing returns is called the “local maximum.” A local maximum is the highest point in the landscape that is reachable from your starting point.
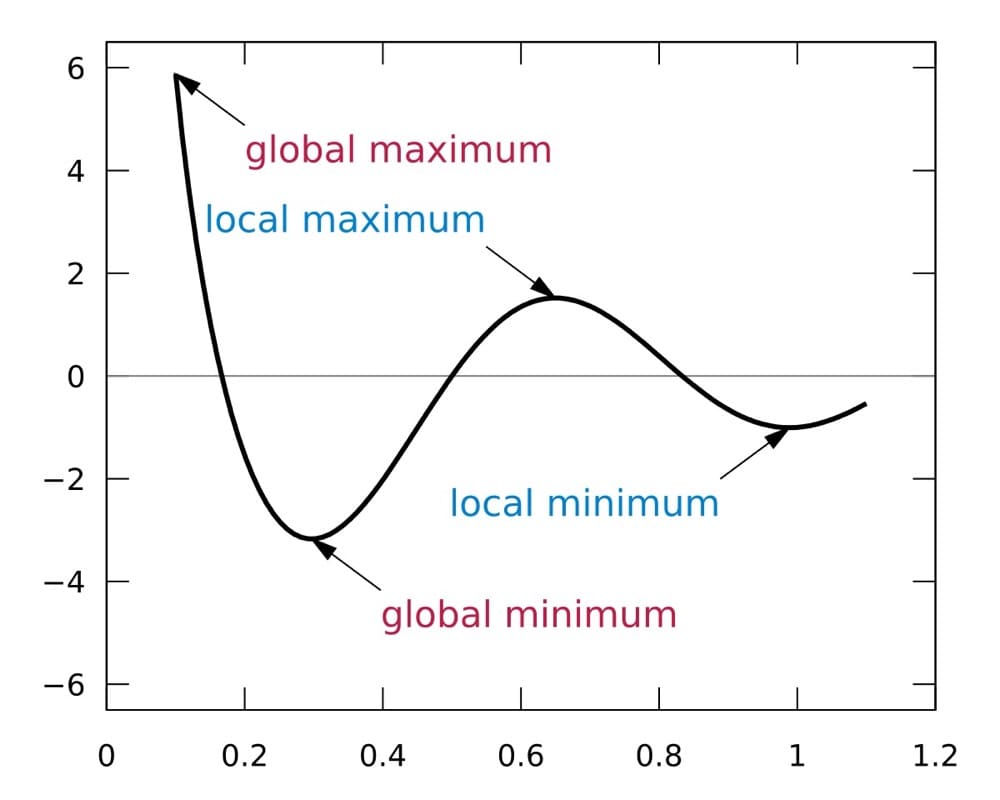
The goal of an iterative test is to find the local maximum for a given change. This can be a very effective way to test things like offer changes or pricing changes, as well as any element you’ve found to be impactful through research or through existence testing.
Basically, you know X element matters, and you know there’s additional wiggle room to improve KPI Y by improving element X. So you take several small and iterative stabs at changing element X until it appears you can’t improve the metric any more (or it’s exceedingly difficult to do so).
An easy example of an iterative test comes from my own website. I run lead magnet popups. I know they drive emails, and there’s likely a point of diminishing returns, but I don’t think I’ve hit it yet. So every few months, I change one variable – either the headline, the offer itself, or the image, in hopes of squeezing out a small lift.
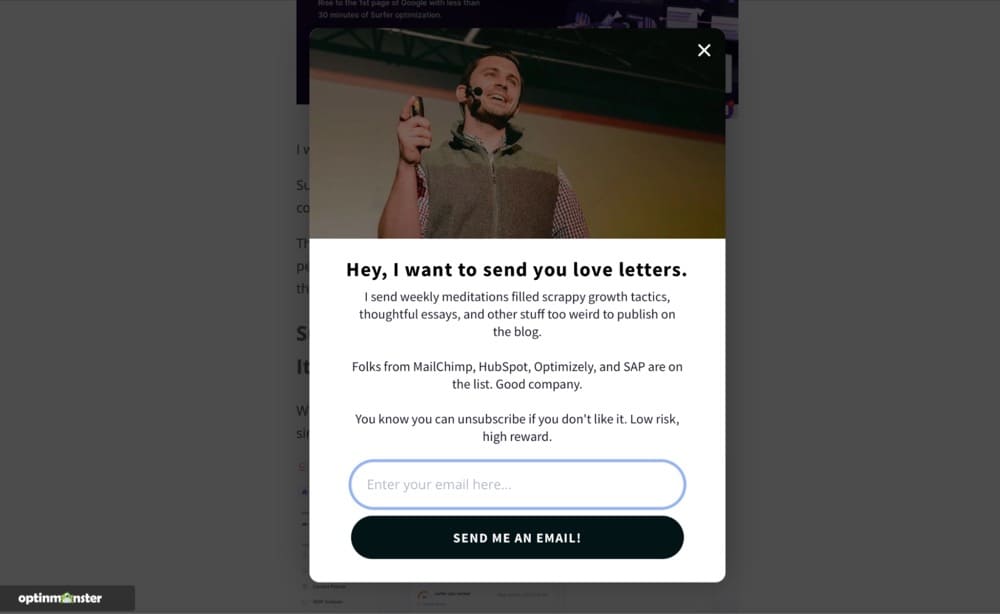
Use cases: optimize targeted elements or experiences by consecutively testing several small iterations to the experience to hit a local maximum.
13. Innovative Test

Opposed to iterative testing, innovative tests seek to find completely new hills to climb.
According to an CXL article, innovative tests are “designed to explore uncharted territory and find new opportunities.”
Innovative tests are all about trying something completely new. They’re usually a bit more risky than other types of experiments, but they can also be very rewarding. If you’re looking for big wins, then innovative testing is the way to go.
Complete homepage or landing page redesigns fall under this category. Discovery testing is a form of innovative testing. Button color tests would be the exact opposite of an innovative test.
An innovative test should make you or your stakeholders slightly uncomfortable (but remember, the beauty of experiments is they are limited duration and cap your downside).
CXL gave an example of an innovative test they ran for a client here:
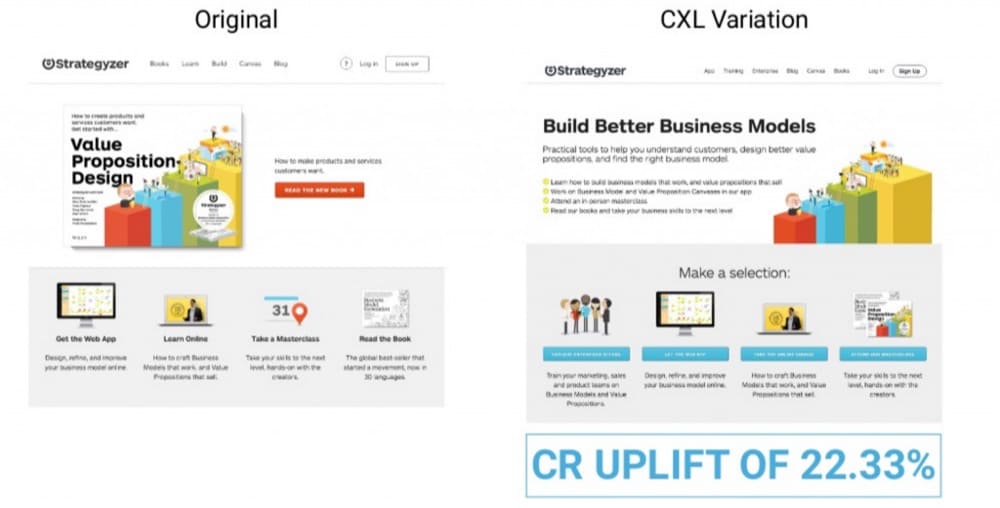
Use cases: take a big swing and find a new “hill” to climb. Wrap together several hypotheses and drastically change an experience.
14. Non-inferiority Test

A non-inferiority test is used to determine if a new treatment is not worse than the standard treatment.
The goal of a non-inferiority test is to show that the new treatment is at least as effective as the standard treatment.
Why would you run a test like this?
Many reasons. The best one I can think of is if you have a variant that is “better” in some other dimension (it’s cheaper to maintain, better adheres to brand standards, etc.), but you want to make sure it doesn’t harm your core business KPIs.
Or in the lens of medical clinical trials, imagine a drug has been developed that costs 1/10 as much as the commonly prescribed medication. As long as it doesn’t perform *worse* than the existing medication, its affordability means it is a much better option to roll out.
Another reason I run these is if the treatment is heavily favored by an executive or stakeholder. Hate to break it to you, but just because we have access to data as experimentation professionals doesn’t mean we avoid the messiness of biased thinking and human politics.
I’m happy to take the occasional HiPPO-submitted test and run it through a lower threshold of certainty like a non-inferiority test. As long as it doesn’t mess up *my* KPIs, there’s no harm in rolling it out, and it wins political favor.
Use cases: cap downside of experiments where another dimension is superior (costliness, preference by stakeholders, user experience, brand, etc.).
15. Feature Flag

Feature flags are a software development technique that allows you to toggle certain features or functionality on or off and test new features in production.
Without getting into a ton of technical detail, they allow you to test features in production or roll them out slowly to smaller subsets of users, while maintaining the ability to quickly scale back or kill the feature if it isn’t working.
In many ways, they are a quality assurance methodology. But then again, in many ways, so are A/B tests.
The term “feature flag” is somewhat of an umbrella term that includes many related “toggle” functionalities, like canary releases, testing in production, continuous development, rollbacks, and feature gates.
Use cases: test new features or experiences before deploying new code into production.
16. Quasi Experiments
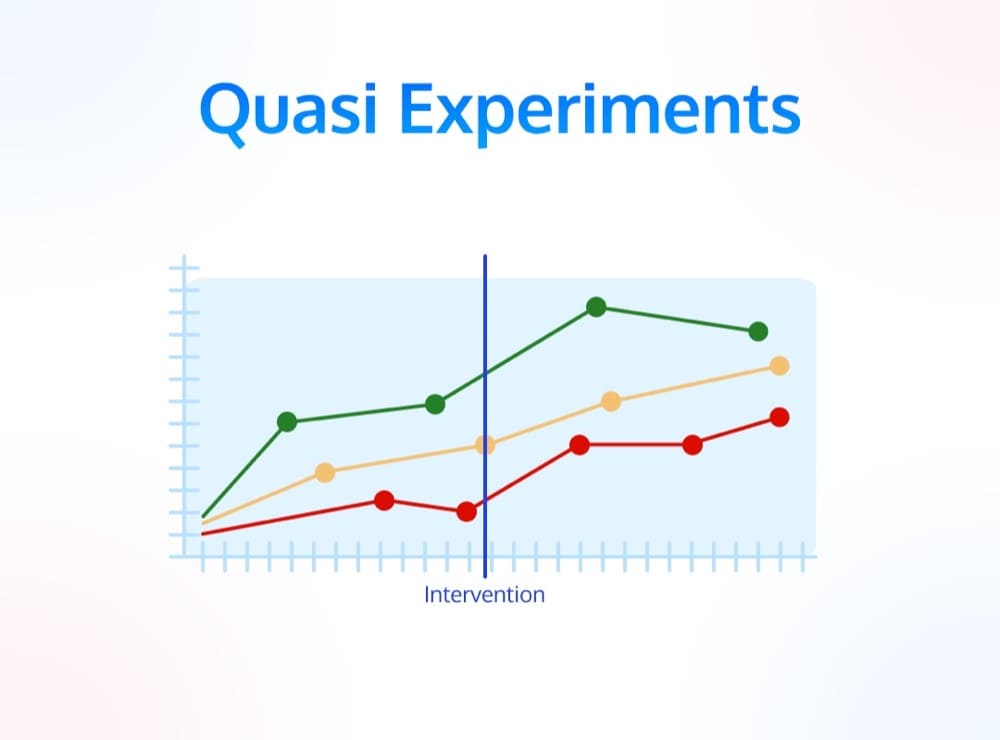
Finally, the most complicated, broad, and hardest to define category of experiments: quasi-experiments.
Quasi-experiments are often used when it’s not possible to randomly assign users to test groups.
For example, if you’re testing a new feature on your website, you can run an A/B test, a feature flag, or even a personalization arm.
But what if you want to test a bunch of SEO changes and see their effects on traffic? Or even further, their impact on blog conversions? What if you want to test the efficacy of outdoor billboard ads?
In a surprisingly large number of cases, it’s difficult if not impossible to set up a tightly organized and truly controlled experiment.
In these cases, we design quasi-experiments to make do with what we have.
In the case of SEO changes, we can use tools like Causal Impact to quantify changes on a time series. Especially if we control our experiment based on pages or some other identifiable dimension, this will give us a good longitudinal idea as to whether or not our intervention worked.
In the case of radio or billboard ads, we can try to select representative geo-locations and quantify the effect over time using similar bayesian statistics.
This is a complex topic, so I’ll link out to two great resources:
Use cases: quantifying impact when a randomized controlled trial isn’t possible or feasible.
Conclusion
I hope this convinced you that A/B testing goes far beyond changing your headline or CTA button to optimize conversion rates.
When you widen your aperture of what experimentation can accomplish, you realize it’s an incredible learning tool.
We can map out impactful elements on a landing page, identify the optimal combination of elements, figure out a new and improved user page path, develop new features and experiences without risking technical debt or a poor user experience, and even test out new marketing channels and interventions off our website or outside our product.
Written By
Alex Birkett
Edited By
Carmen Apostu
