57 Common A/B Testing Mistakes & How to Avoid Them
Are you running A/B tests but not sure if they’re working properly?
Do you want to learn the common mistakes when A/B testing so that you don’t lose valuable time on a broken campaign?
Well, good news! In this article, we’re going to walk you through 57 common (and sometimes uncommon) A/B testing mistakes that we see, so you can either sidestep them or realize when they are happening and fix them fast.
We’ve broken these down into 3 key sections:
- Mistakes before you start testing,
- Issues that can happen during the test,
- And errors you can make once the test is finished.
You can simply read through and see if you’re making any of these yourself.
And remember:
Every failure is a valuable lesson, both in testing and in set up mistakes. The key is to learn from them!
So let’s dive in…
Common A/B Testing Mistakes That Can Be Made Before You Even Run Your Test
#1. Pushing something live before testing!
You might have a fantastic new page or website design and you’re really eager to push it live without testing it.
Hold off!
Run a quick test to see how it works first. You don’t want to push a radical change live without getting some data, or you could lose sales and conversions.
Sometimes that new change can be a substantial dip in performance. So give it a quick test first.
#2. Not running an actual A/B test
An A/B test works by running a single traffic source to a control page and a variation of that page. The goal is to find if the change you implemented makes the audience convert better and take action.
The thing is, to make sure this test is controlled and fair, we need to run that test with specific parameters. We need the same traffic sources viewing the campaign during the same period of time so that we don’t have any external factors affecting one test and not the other.
Some people make the mistake of running a test in sequence. They run their current page for X amount of time, then the new version for X time after that, and then measure the difference.
These results are not entirely accurate as many things could have happened during those test windows. You could get a burst of new traffic, run an event, causing the 2 pages to have wildly different audiences and results.
So make sure you’re running an actual A/B test where you’re splitting the traffic between your 2 versions and testing them at the exact same time.
#3. Not testing to see if the tool works
No testing tool is 100% accurate. The best thing you can do when starting out is to run an A/A test to see how precise your tool is.
How? Simply run a test where you split traffic 50:50 between a single page. (Make sure it’s a page that your audience can convert on so you can measure a specific result.)

Why?
Because both sets of your audience are seeing the exact same page, the conversion results should be identical on both sides of the test, right?
Well, sometimes they’re not, which means that your tool may be set up incorrectly. So go ahead and check your testing tool before running any campaigns.
#4. Using a low-quality tool and content flashing
Some tools are just not as good as others. They do the job but struggle under traffic load or ‘blink’ and flicker.

This can actually cause your test to fail, even if you have a potential winning variant.
Let’s say you’re split testing an image on your page. The control page loads fine, but the variation flickers between the new test image and the original for just a fraction of a second. (Or maybe every time the user scrolls up and down the page.)
This can be distracting and cause trust issues, lowering your conversion rate.
In fact, your new image could even convert better in theory, but the tool flickering is lowering the results, giving you an inaccurate test of that image.
Make sure you have a good enough tool to test with.
(This is such an important user experience factor that Google is currently adjusting their rankings for sites that don’t have flickering or moving elements).
#5. No test QA
A super simple mistake, but have you checked that everything works?
- Have you been through the sales process?
- Have others? (And on uncached devices because sometimes what’s saved in your browser is not what the page looks like.)
- Are the pages loading ok? Are they slow? Are the designs messed up?
- Do all the buttons work?
- Is the revenue tracking working?
- Have you checked that the page works on multiple devices?
- Do you have error reporting in place if something breaks?
This is all worth checking out BEFORE you start running traffic to any campaign.
Get our Quality Assurance Checklist for A/B Tests. It’s a fillable PDF you’ll want to go back to every time you QA a test.
#6. Does the new treatment/variation work?
Likewise, have you gone through and tested that your new variation works before you run a test?
It’s may be an overlooked part of QA testing, but campaigns can often run with broken buttons, old links, and more. Check first, then test.
#7. Not following a hypothesis and just testing any old thing
Some people just test anything without really thinking it through.
They get an idea for a change and want to test it out, but with no real analysis of how the page currently converts, or even why the change they are testing could make a difference. (It could be that they lower the conversion but don’t even know it, as they don’t have a baseline result tracked yet).
Forming a hypothesis of where an issue lies, the cause of it, and how you can resolve it will make a huge difference to your testing program.

#8. Having an untestable hypothesis
Not every hypothesis is correct. This is fine. In fact, the word literally means ‘I have an idea based on X information and I think Y might happen in Z circumstance’.
But you’ll need a hypothesis that is testable, meaning it can be proven or disproven through testing. Testable hypotheses put innovation into motion and promote active experimentation. They could either result in success (in which case your hunch was correct) or failure – showing you were wrong all along. But they will give you insights. It may mean your test needs to be executed better, your data was incorrect/read wrong, or you found something that didn’t work which often gives insight into a new test that might work far better.
#9. Not setting a clear goal for your test in advance
Once you have a hypothesis, you can use this to align with a specific result you want to achieve.
Sometimes people just run a campaign and see what changes, but you will definitely get more leads/conversions or sales if you have clarity on which specific element you want to see a lift on.
(This also stops you from seeing a drop in an important element but considering the test a win because it ‘got more shares’.)
Speaking of which…
#10. Focusing on superficial metrics
Your test should always be tied to Guardrail metrics or some element that directly affects your sales. If it’s more leads then you should know down to the dollar what a lead is worth and the value of raising that conversion rate.
At the same time, metrics that don’t connect to or drive a measurable outcome should usually be avoided. More Facebook likes don’t necessarily mean more sales. Remove those social share buttons and just watch how many more leads you get. Be wary of vanity metrics and remember that just because one leak is fixed doesn’t mean there isn’t another one elsewhere to address as well!
Here’s Ben Labay’s list of common guardrail metrics for experimentation programs:
#11. Only using quantitative data to form test ideas
Using quantitative data to get ideas is great, but it’s also slightly flawed. Especially if the only data that we use is from our analytics.
Why?
We can know from our data that X amount of people didn’t click, but we might not know why.
- Is the button too low down the page?
- Is it unclear?
- Does it align with what the viewer wants?
- Is it even working?
The best testers also listen to their audience. They find out what they need, what moves them forward, what holds them back, and then use that to formulate new ideas, tests, and written copy.
Sometimes your users are held back by trust issues and self-doubts. Other times, it’s clarity and broken forms or bad designs. The key is these are things that quantitative data can’t always tell you, so always ask your audience and use it to help you plan.
#12. Copying your competitors
Ready for a secret?
A lot of the time your competitors are just winging it. Unless they have someone who has run long-term lift campaigns, they might be just trying things to see what works, sometimes without using any data for their ideas.
And even then, what works for them, might not work for you. So yes, use them for inspiration but don’t limit your test ideas to only what you see them doing. You can even go outside of your industry for inspiration and see if it sparks some hypotheses.
#13. Only testing ‘industry best practices’
Again, what works for one is not what always works for another.
For example, slider images usually have terrible performance but, on some sites, they can actually drive more conversions. Test everything. You have nothing to lose and everything to gain.
#14. Focusing on small impact tasks first, when high impact large reward/low hanging fruit is available
We can all be guilty of focusing on the minutia. We might have a page that we want to perform better and test layout designs and images and even button colors. (I personally have a sales page that is in its 5th iteration.)
The thing is, there are probably way more important pages for you to be testing right now.
Prioritize impact most of all:
- Will this page directly affect sales?
- Are there other pages in the sales process massively underperforming?
If so, focus on those first.
A 1% lift on a sales page is great, but a 20% lift on the page that gets them there could be far more important. (Especially if that particular page is where you are losing most of your audience.)
Sometimes we’re not only looking for more lift but to fix something that’s a bottleneck instead.
Test and improve the biggest impact, lowest hanging fruit first. That’s what agencies do and it’s why they perform the same number of tests as in-house teams, but with a higher ROI. Agencies get 21% more wins for the same volume of tests!
#15. Testing multiple things at once and not knowing which change caused the result
There’s nothing wrong with doing radical tests where you change multiple things at once and do an entire page redesign.
In fact, these radical redesigns can sometimes have the biggest impact on your ROI, even if you’re a low-traffic site, and especially if you are plateaued and can’t seem to get any more lift.
But bear in mind, not every A/B test should be for a radical change like this. 99% of the time we’re just testing a change of a single thing, like
- New headlines
- New images
- New layout of the same content
- New pricing, etc.
The key when doing a single element test is just that though. Keep your test to just ONE element change so that you can see what is making the difference and learn from it. Too many changes and you don’t know what worked.
#16. Not running a proper pre-test analysis
Do you have enough visitors in your test group? Is the test even worth your while?
Do the math! Make sure you have enough traffic before running a test – otherwise it’s just wasted time and money. Many tests fail because of insufficient traffic or poor sensitivity (or both).
Perform a pre-test analysis to determine the Sample Size and Minimum Detectable Effect for your experiment. An A/B Testing Significance Calculator like Convert’s will tell you the Sample Size and MDE for your test, which will help you decide if it’s worth running. You can also use this information to determine how long the test should run and how small a lift you wouldn’t want to miss before concluding that a test was successful or not.
#17. Mislabelling the tests
A super simple mistake but it happens. You mislabel the tests and then get the wrong results. The variation wins but it’s named the control, and then you never implement the win and stay with the loser!
Always double-check!
#18. Running tests to the wrong URL
Another simple mistake. Either the page URL has been entered incorrectly, or the test is running to a ‘test site’ where you made your changes and not to the live version.
It might look ok for you, but it won’t actually load for your audience.
#19. Adding arbitrary display rules to your test
Again, you need to test one thing with your treatment and nothing else.
If it’s an image, then test the image. Everything else should be the same, including the time of day when people can see both pages!
Some tools allow you to test different times of day to see how traffic performs in different time frames. This is helpful if you want to see when your best traffic is on your site, but not helpful if pages are being split by who sees them AND having different variations.
For example, our own blog traffic goes down on weekends (like most business blogs).
Imagine if we ran a test on Mon-Wed on the control page, and then showed traffic from Fri-Sun on the treatment? It would have much lower traffic to test with, and probably way different results.
#20. Testing the wrong traffic for your goal
Ideally, when running a test, you want to make sure you’re only testing a single segment of your audience. Usually, it’s new organic visitors, to see how they respond their first time on your site.
Sometimes you might want to test repeat visitors, email subscribers, or even paid traffic. The trick is to only test one of them at a time so you can get an accurate representation of how that group performs with that page.
When you set up your test, select the audience you want to work with and remove any others that might pollute the result, such as returning visitors.
#21. Failing to exclude returning visitors into a test and skewing the results
We call this sample pollution.
Basically, if a visitor sees your site’s page, returns and sees your variation, then they will respond very differently than if they only saw one of them.
They can be confused, bounce off, or even convert higher, simply because of those extra interactions.
The thing is, it causes your data to become polluted and less accurate. Ideally, you want to use a tool that randomizes which page they see but then always shows them that same version until the test is over.
#22. Not removing your IPs from the test
Speaking of sample pollution, here’s another way to pollute your data (and it’s a good practice for analytics anyway).
Make sure to block you and your staff’s IP addresses from your analytics and testing tool. The last thing you want is for you or a team member to ‘check in’ on a page and be tagged in your test.
#23. Not segmenting the control group variations (Network Effect)
Another pollution option that’s rare but can happen, especially if you have a network for your audience.
Here’s an example.
Let’s say you have a platform where your audience can communicate. Perhaps a Facebook page or comments section, but EVERYONE can access it.
In this situation, you might have people seeing one page and others seeing a variation, but all of them are on the same social network. This can actually skew your data as they can affect each other’s choices and interactions with the page. Linkedin has been segmenting its audience when testing new features to prevent network effect issues.
Ideally, you want to separate the communication between the 2 test groups until the test is completed.
#24. Running tests during seasonal events or major site/platform events
Unless you’re testing for a seasonal event, you never want to run a test campaign during the holidays or any other major event, such as a special sale or world event happening.
Sometimes you can’t help it. You’ll have a test run and Google just implements a new core update and messes with your traffic sources mid-campaign *cough*.
The best thing to do is simply rerun after that all dies down.
#25. Ignoring cultural differences
You might have a goal for a page, but are also running a global campaign with multiple variations showing in different languages and different countries.
You need to take this into account when running your test. Some changes can be made globally, such as a simple layout shift or adding trust signals, etc.
Other times, you need to take into account cultural points of difference. How people see the layout, how they view images, and the avatars on your page.
Netflix does this with the thumbnails of all of their shows, testing for different elements that may appeal to different audiences (featuring specific actors famous to that country instead).

What gets clicks in one country can be incredibly different in others. You don’t know until you test though!
#26. Running multiple connected campaigns at the same time
It’s easy to get excited and want to run multiple tests at once.
Just remember: You can run multiple tests for similar points in the sales process at the same time, but don’t run multiple tests for multiple connected points in the funnel.
Here’s what I mean.
You could quite easily run tests on every lead generation page you have, all at the same time.
However, you wouldn’t want to be testing lead pages, sales pages, and checkout pages all at once as this can introduce so many different elements into your testing process, requiring massive volumes of traffic and conversions to get any useful insight.
Not only that, but each element can cause different effects on the next page, both good and bad. Unless you have hundreds of thousands of visitors a week, you’ll probably struggle to get accurate results.
So be patient and test only one stage at a time or pages that are not connected in the process.
Sidenote:
Convert allows you to exclude people in one experiment from seeing any others. So you can in theory test the full sales cycle and then only see the control of the other pages.
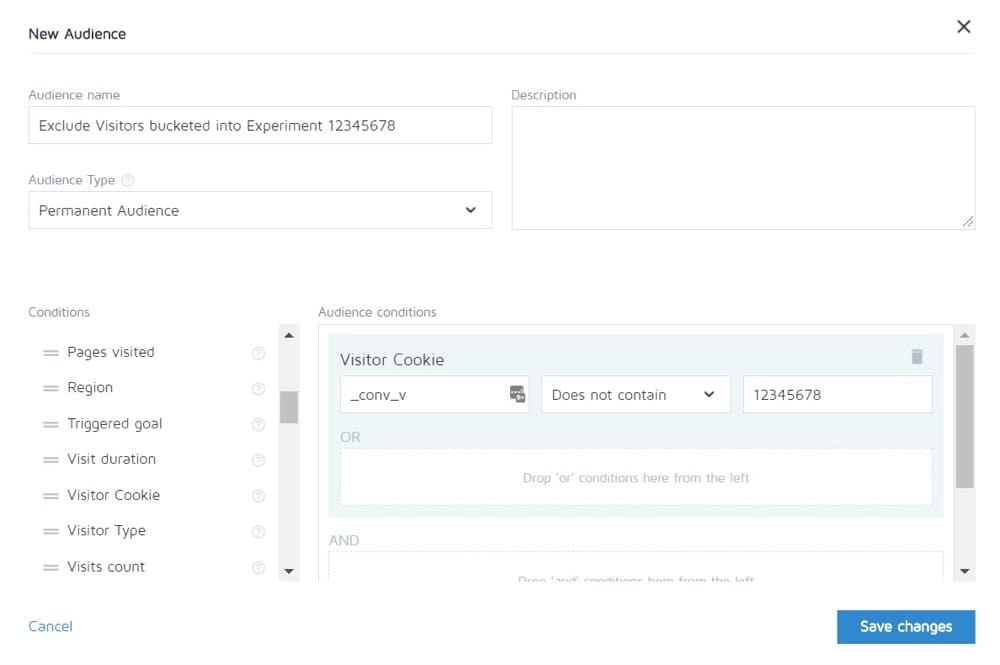
#27. Unequal traffic weighting
It doesn’t matter if you’re running an A/B, an A/B/n, or a Multivariate test. You need to allocate equal traffic volume to each version so that you can get an accurate measurement.
Set them up to be equal from the start. Most tools will allow you to do this.
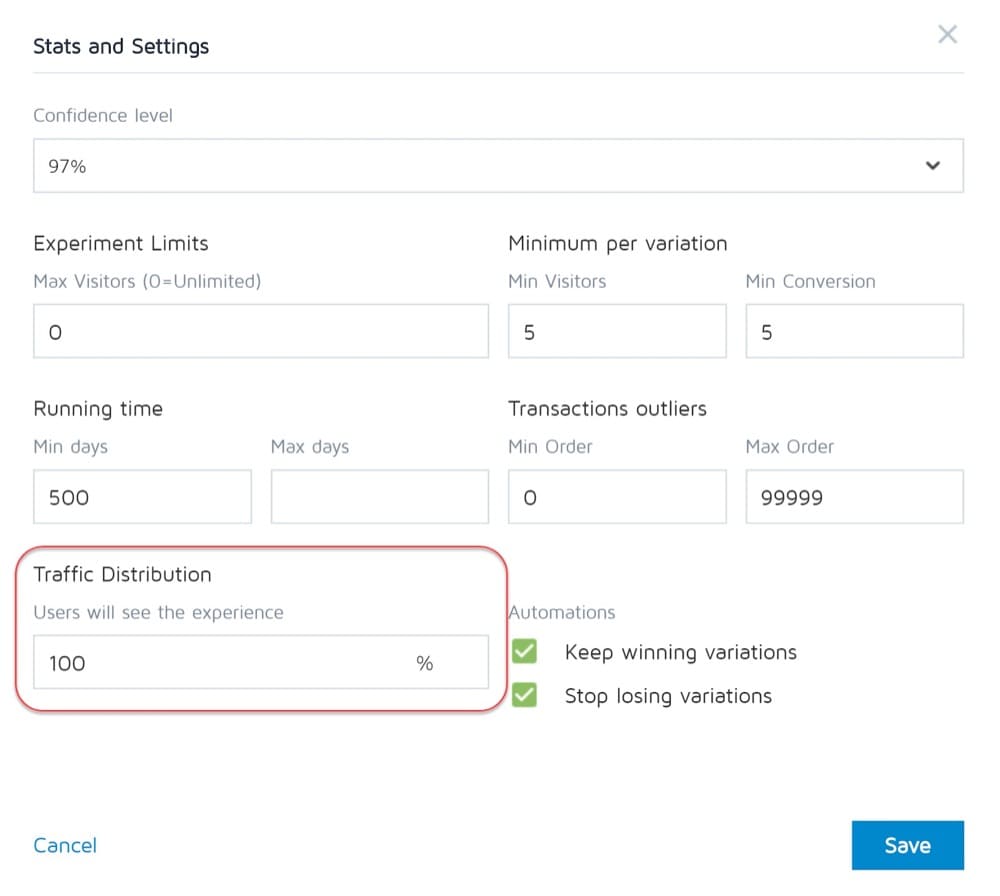
Common A/B Testing Mistakes You Can Make During Your Test
#28. Not running for long enough to get accurate results
There are 3 important factors to take into account when you want to test and get accurate results:
- Statistical Significance,
- Sales Cycle, and
- Sample Size.
So let’s break it down.
Most people end tests once their testing tool tells them that one result is better than the other AND the result is statistically significant i.e if the test continues to perform like this, then this is a definite winner.
The thing is you can hit ‘stat sig’ pretty fast sometimes with just a small amount of traffic. Randomly all the conversions happen on one page and none on the other.
It won’t always stay like this though. It could be that the test launched, it’s payday and you got a bunch of sales on that day.
This is why we need to take the sales cycle into account. Sales and traffic can fluctuate depending on the day of the week or the month. To get a more accurate representation of how your test is running, you ideally need to run between 2 to 4 weeks long.
Finally, you have the sample size.
If you’re running your test for a month then you’re probably going to get enough traffic to get accurate results. Too little and the test just won’t be able to give you a confidence level that it will perform as it should.
So as a rule of thumb,
- Go for a 95% confidence rating.
- Run for a month.
- Figure out what sample size you need in advance and don’t stop the test until that’s hit OR you get some amazing result that proves without a shadow of a doubt that you have a winner.
#29. Helicopter monitoring/peeking
Peeking is a term used to describe when a tester has a look at their test to see how it’s performing.
Ideally, we never want to look at our test once running, and we never make a decision on it until it’s finished a full cycle, with the right sample size and it’s hit statistical significance.
However… What if the test isn’t running?
What if something is broken?
Well, in that case, you don’t really want to wait a month to see it’s broken, right? This is why I always check to see if a test is getting results in the control and variation, 24 hours after I set it to run.
If I can see that they are both receiving traffic and getting clicks/conversions, then I walk off and let it do its thing. I make NO decisions until the test has run its course.
#30. Not tracking user feedback (especially important if the test is affecting a direct, immediate action)
Let’s say the test is getting clicks and the traffic is distributed, so it *looks* like it’s working, but suddenly you start getting reports that people can’t fill out the sales form. (Or better still, you got an automated alert that a guardrail metric has dropped way below acceptable levels.)
Well, then your first thought should be that something is broken.
It’s not always. You might be getting clicks from an audience that doesn’t resonate with your offer, but just in case, it’s worth checking that form.
If it’s broken then fix it and restart.
#31. Making changes mid-test
It might have been clear from those last few points, but we never want to make any changes to a test once it’s gone live.
Sure, something might break, but that’s the only change we should ever make. We don’t change the design, or copy, or anything.
If the test is working, let it run and let the data decide what works.
#32. Changing the traffic allocation % mid-test or removing poor performers
Just like we don’t change the pages being tested, we don’t remove any variations or change the traffic distribution mid-test either.
Why?
Let’s say you’re running an A/B/n test with a control and 3 variations. You start the test and after a week you naughtily sneak a peek and notice that 2 versions are doing great and one is doing poorly.
Now it would be tempting to turn off the ‘losing’ variation and redistribute the traffic among the other variations, right? Heck… you might even want to take that extra 25% of the traffic and just send it to the top performer, but don’t do it.
Why?
Not only will this redistribution affect the test performance, but it can directly affect the results and how they appear on the reporting tool.
All the users that were previously bucketed to the removed variant will need to be re-allocated to a variant and will be seeing a changed webpage in a short amount of time, which could affect their behavior and subsequent choices.
That’s why you never change traffic or turn off variations mid-way through. (And also why you shouldn’t be peeking!)
#33. Not stopping a test when you have accurate results
Sometimes you just forgot to stop a test!
It keeps on running and feeding 50% of your audience to a weaker page and 50% to the winner. Oops!
Fortunately, tools like Convert Experiences can be set up to stop a campaign and automatically show the winner once it hits certain criteria (like sample size, stat sig, conversions, and time frame).
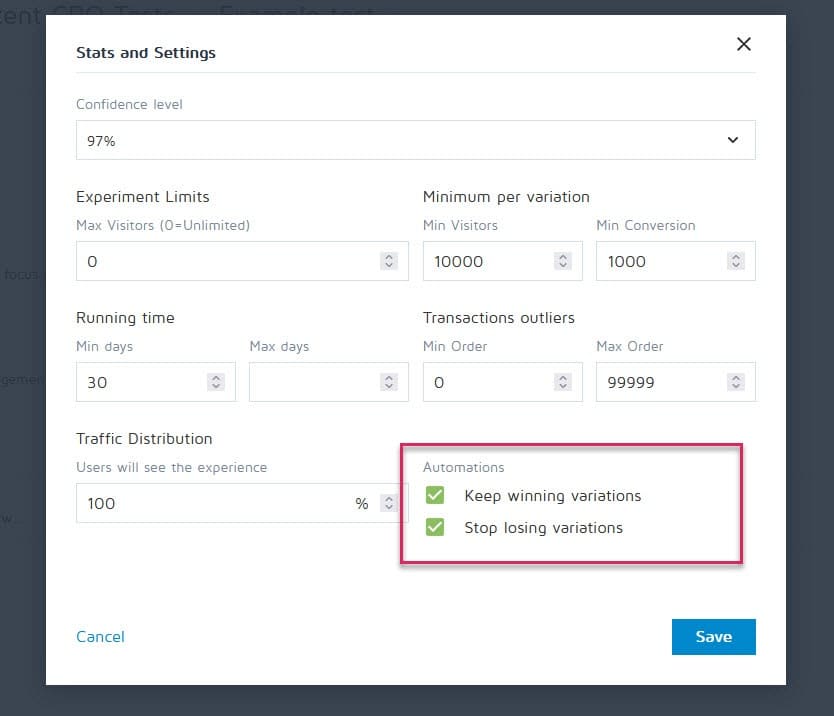
#34. Being emotionally invested in losing variations
As testers, we need to be impartial. Sometimes, however, you might have a particular design or idea that you just love and are convinced that it should have won so you keep extending the test out longer and longer to see if it pulls ahead.
Pull the bandaid off.
You might have a good idea that just needs improving, but you can’t do that until you end the current test.
#35. Running tests for too long and tracking drops off
Here’s another potential sample pollution issue.
If you run a test for longer than 4 weeks, there is a chance that you might see users’ cookies drop off. This can cause a lack of tracking of events but they may even return and pollute the sample data again.
#36. Not using a tool that allows you to stop/implement the test!
Another rare issue.
Some testing programs insist on creating hard-coded tests. i.e a developer and engineer build the campaign from scratch.
It’s not great, however, when the test is over and you need to wait for that same developer to turn it off and install the winning variation. Not only is this frustrating, but it can seriously slow down the number of tests you can run and even the ROI of the page while waiting for it to go live.
Common A/B Testing Mistakes You Can Make After Your Test Is Finished
#37. Giving up after one test!
9 out of 10 tests are usually a failure.
That means you need to run 10 tests to get that winner. It takes effort but it’s always worth it, so don’t stop after one campaign!
#38. Giving up on a good hypothesis before you test all versions of it
A failure can simply mean your hypothesis is correct but needs to be executed better.
Try new ways, new designs, new layout, new images, new avatars, new language. You have the idea and see if you can execute it better.
It took CXL 21 iterations to improve their client’s page, but it took them from a 12.1% to 79.3% conversion rate.
#39. Expecting huge wins all the time
The fact of the matter is you might only get a huge win 1 out of every 10 or more winning campaigns.
This is ok. We keep testing and we keep improving, because even a 1% increase compounds over time. Improve on it and get it to 2% and you’ve now doubled the effectiveness.
Which types of tests yield the best results?
The truth is, different experiments have varying effects. According to Jakub Linowski’s research from over 300 tests, layout experiments tend to lead to better results.
What’s the most difficult screen type to optimize? The same research reveals it’s checkout screens (with a median effect of +0.4% from 25 tests).
#40. Not checking validity after the test
So the test is finished. You ran for long enough, saw results, and got stat sig but can you trust the accuracy of the data?
It could be that something was broken mid way through testing. It never hurts to check.
#41. Not reading the results correctly
What are your results really telling you? Failing to read them correctly can easily take a potential winner and seem like a complete failure.
- Dive deep into your analytics.
- Look at any qualitative data you have.
What worked and what didn’t? Why did it happen?
The more you understand your results, the better.
#42. Not looking at the results by segment
It always pays to dive a little deeper.
For example, a new variant could seem to be converting poorly, but on mobile, it has a 40% increase in conversions!
You can only find that out by segmenting it down into your results. Look at the devices used and the results there. You might find some valuable insights!
Just be aware of the significance of your segment size. You might not have had enough traffic to each segment to trust it fully, but you can always run a mobile-only test (or whichever channel it was) and see how it performs.
#43. Not learning from results
Losing tests can give you insight into where you need to improve further or do more research. The most annoying thing as a CRO is seeing clients who refuse to learn from what they’ve just seen. They have the data but don’t use it…
#44. Taking the losers
Or worse, they take the losing variation.
Maybe they prefer the design and the conversion rate is only 1% different but over time those effects compound. Take those small wins!
#45. Not taking action on the results
Even worse again?
Getting a win but not implementing it! They have the data and just do nothing with it. No change, no insight, and no new tests.
#46. Not iterating and improving on wins
Sometimes you can get a lift but there’s more to be had. Like we said earlier, it’s very rare that every win will give you a double-digit lift.
But that doesn’t mean that you can’t get there by running new iterations and improvements and clawing your way up 1% at a time.
It all adds up so keep on improving!
#47. Not sharing winning findings in other areas or departments
One of the biggest things we see with hyper-successful/mature CRO teams is that they share their winnings and findings with other departments in the company.
This gives other departments insights into how they can also improve.
- Find some winning sales page copy? Preframe it in your adverts that get them to the page!
- Find a style of lead magnet that works great? Test it across the entire site.
#48. Not testing those changes in other departments
And that’s the key here. Even if you share insights with other departments, you should still test to see how it works.
A style design that gives lift in one area might give a drop in others, so always test!
#49. Too much iteration on a single page
We call this hitting the ‘local maximum’.
The page you’re running tests on has plateaued and you just can’t seem to get any more lift from it.
You can try radical redesigns, but what next?
Simply move onto another page in the sales process and improve on that. (Ironically this can actually prove to give a higher ROI anyway.)
Taking a sales page from a 10% to 11% conversion can be less important than taking the page that drives traffic to it from 2% to 5%, as you will essentially more than double the traffic on that previous page.
If in doubt, find the next most important test on your list and start improving there. You may even find it helps conversion on that stuck page anyway, simply by feeding better prospects to it.
#50. Not testing enough!
Tests take time and there’s just only so many that we can run at once.
So what can we do?
Simply reduce the downtime between tests!
Complete a test, analyze the result, and either iterate or run a different test. (Ideally, have them queued up and ready to go).
This way you’ll see a much higher return for your time investment.
#51. Not documenting tests
Another habit mature CRO teams have is creating an internal database of tests, which includes data about the page, the hypothesis, what worked, what didn’t, the lift, etc.
Not only can you then learn from older tests, but it can also stop you from re-running a test by accident.
#52. Forgetting about false positives and not double-checking huge lift campaigns
Sometimes a result is just too good to be true. Either something was set up or recording wrong, or this just happens to be that 1 in 20 tests that gives a false positive.
So what can you do?
Simply re-run the test, set a high confidence level, and make sure you run them for long enough.
#53. Not tracking downline results
When tracking your test results, it’s also important to remember your end goal and track downline metrics before deciding on a winner.
A new variant might technically get fewer clicks through but drives more sales from the people who do click.
In this instance, this page would actually be more profitable to run, assuming the traffic that clicks continues to convert as well…
#54. Fail to account for primacy and novelty effects, which may bias the treatment results
Let’s say you’re not just targeting new visitors with a change, but all traffic.
We’re still segmenting them so 50% see the original and 50% see the new version, but we’re allowing past visitors into the campaign. This means people who’ve seen your site before, read your content, seen your calls to action, etc.
Also, for the duration of the campaign, they only see their specific test version.
When you make a new change, it can actually have a novelty effect on your past audience.
Maybe they see the same CTA all the time and now just ignore it, right? In this case, a new CTA button or design can actually see a lift from past visitors, not because they want it more now, but because it’s new and interesting.
Sometimes, you might even get more clicks because the layout has changed and they’re exploring the design.
Because of this, you will usually get an initial lift in response, but which dies back down over time.
The key when running your test is to segment the audience after and see if the new visitors are responding as well as the old ones.
If it’s much lower, then it could be a novelty effect with the old users clicking around. If it’s on a similar level, you might have a new winner on your hands.
Either way, let it run for the full cycle and balance out.
#55. Running consideration period changes
Another thing to consider when testing is any variant that might change the audience’s consideration period.
What do I mean?
Let’s say you normally don’t get immediate sales. Leads could be on a 30-day or even longer sales cycle.
If you’re testing a call to action that directly affects their time to consider and buy, that’s going to skew your results. For one thing, your control might get sales but be outside of the testing period, so you miss them.
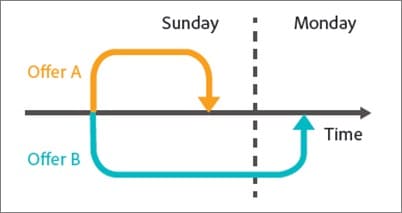
Another scenario is if you have a CTA that offers a deal, a price point of anything else that makes them want to take action now, then this will almost always skew your results to make this version seem like it’s converting far better.
Keep this in mind and look through your analytics during and after the test to be sure.
#56. Not retesting after X time
This is less about a certain page or test mistake, but more about testing philosophy.
Yes, you might have an awesome page, and yes, you might have done 20 iterations on it to get it where it is today.
The thing is in a few years you may need to overhaul that entire page again. Environments change, language and terms used, the product can be tweaked.
Always be ready to go back into an old campaign and retest. (Another reason why having a testing repository works great.)
#57. Only testing the path and not the product
Almost all of us focus on the path to the sale and test for that. But the reality is the product can also be A/B tested and improved and can even offer a higher lift.
Think of the iPhone.

Apple tested its website and improved on it, but it’s the product iterations and improvements that continue to drive even more lift.
Now, you might not have a physical product. You might have a program or digital offer, but learning more about your audience’s needs and testing that, then taking it back to your sales page can be HUGE in terms of lift.
Conclusion
So there you have it. The 57 common and uncommon A/B testing mistakes that we see and how you can avoid them.
You can use this guide to help you sidestep these issues for all future campaigns.

Written By
Daniel Daines Hutt

Edited By
Carmen Apostu
