How to Treat Qualitative Data & Quantitative Data for Winning A/B Tests?
If we break it down to its core concepts, CRO is less about conversions and more about understanding your audience and how they interact with your website.
The more you understand them, what they want and how they act on your site, the better customer experience and offers you can provide.
This means that our primary goal as testers is to find out as much information as possible. The more data we have, the better we can plan out tests and try to see a lift in results.
The problem?
We’re not always great at collecting or understanding that data. Maybe we don’t know the tools to use, the processes to find the information, or perhaps we’re not analyzing and getting accurate insights, either from a lack of experience or worse, adding in our own bias that corrupts the results.
That’s what we’re going to cover in today’s guide: How to collect information on your audience, understand it, and use it. We’ll even deep dive and look at other testers and their processes so you can glean even more ideas and insights for your new tests.
Keep reading to find out more, or click here to learn “how to use data to drive winning A/B tests”.
When it comes to testing and finding out information for your site or app, there are two types of data that we want to look at.
What Is Quantitative Data?
Quantitative data is all about raw numbers. Our goal when analyzing this is to provide direct feedback on how each interaction is performing on our site and to assign an actual numerical value to it
Examples of quantitative data analysis could be:
- Measuring traffic to a page
- That traffic’s bounce rate
- The CTR
- Subscriber rate
- Sales rate
- Average sale value.
Most testing programs will start with both a technical analysis to get data on what’s working or broken on a website, and then a quantitative analysis to get a baseline for how the site currently performs, before moving on to a qualitative analysis.
What is Qualitative Data?
Quantitative data gives us the raw numbers of how the page or app performs, but it doesn’t tell us why those things are happening.
That’s where qualitative data analysis comes in. It helps us understand why things happen (good or bad) so that we can then form a hypothesis of how to improve them.
Examples of qualitative data are
- User research
- Scroll maps
- Click tracking
- Heat mapping
- Surveys.
The goal is to simply get a better understanding of the audience and how they interact, so we can spot potential issues on the site usage, or learn any external issues that may affect their actions on site.
For example, although we know a CTA isn’t getting many clicks, it is only through customer interviews that we find out that the language isn’t clear or doesn’t resonate with the audience.
With this video from Convert’s A/B testing course, you will learn the difference between quantitative data and qualitative data and their implications in A/B testing.
What Is the Right Way to Use Data in A/B Testing?
Although it looks like we’re only tracking specific conversion events or monitoring user behavior, the goal is to combine both quantitative and qualitative data. Perhaps to find technical faults or common issues, but ideally, we combine them so that we can educate ourselves and gain a more holistic insight into our audience.
We don’t just want immediate information either. We want to find out why things are happening and then take it one step further to find the root cause.
Let’s say that we do quantitative research and we see that the conversion rate on a page is low. Is the offer or product just not wanted? Or do we need to improve the process?
We then run a heatmap on the landing page and see that the majority of the audience don’t click a specific CTA, and so we can hypothesize why. Maybe the language isn’t clear?
But then on a deeper inspection, we see that for some devices it’s simply off-screen, while on others, it doesn’t stand out enough to even be clear that it is a button to be pressed.
- If all we looked at was the qualitative data, then we would just think it’s a low CTR.
- If all we looked at was the qualitative data, then we might assume people are just not clicking.
But by combining them, we can see much deeper. (This is how we really understand data in A/B testing.)
The old idiom is true in that “what gets measured gets managed”. The key, of course, is to make sure we’re not making decisions based on limited or flawed data sets so ALWAYS look at multiple data sources.
Learning to slow down, ask why, and let the data sink in will help you become a much better tester and problem solver.
Rather than try to find the answer immediately, ask yourself if you have enough information:
- Do your users have an easily fixable issue (broken button or weak CTA) or could there be more to this that could also be improved on?
- Do you have an inherent bias or previous experience that is affecting your initial ideas?
- Could you find out more about your audience first?
What if by looking deeper at this CTA and layout issue, you find that the majority of your audience uses outdated mobile devices with different screen resolutions and loading speeds? It could be that they are missing most of your content and interactions and not just your CTA and sales pages. Even your social media and blog content could be affected!
Go deeper again. Why do they have these devices? Can they not afford a more expensive device? Is it not important to them? If not, then what is?
Don’t just try to make all your decisions off what you have so far. Take your time, think and dive deeper with any result that you get. Find the reason why.
Big Mistakes to Avoid when Collecting & Analyzing Data
Now, don’t worry if you’re the type of tester who tries to find an immediate insight from their initial research as you are not alone in this.
This is just one of a few recurring issues that most people make when trying to collect or understand their data…
Issue #1: Collecting Data to Prove an Opinion
Are you using data to find out new insights? Or are you using data to validate current ideas?
It’s ok to use data to validate an idea. That’s the goal of the hypothesis. We have an idea of what is wrong and how to fix it, and so we try to prove that with the test and its results.
But don’t forget the scientific method! We can’t become attached to our ideas and opinions. We need to trust the data and find the real reason. That’s what we care about. It’s ok to be ‘wrong’ with a hypothesis. Finding out a different insight from a failed test simply teaches you more about your audience!
Just be wary of the data telling you one thing, but you skewing it to try and prove something else.
Issue #2: Sponsoring Analysis without Clearly Articulating the Problem
A common issue in testing (and even most businesses) is that the person who analyzes the data is not always the analyst.
Instead, the analyst is used as a medium to pull information into reports for a 3rd party who is trying to solve a problem. (They become a glorified dashboard almost.)
Here’s an example:
- Your boss has a goal and a problem.
- They have a rough idea of the solution and the cause, and so ask the analyst for data on XYZ, but without context. They’re trying to figure out if this problem and solution might work.
- Usually, there is back and forth to request more data. This request either falsely supports the idea, or no further understanding has happened.
- And so new tests or ideas are brought forward, and the issue remains unsolved.
Not great, right?
But imagine if the boss came to the analyst with the context of the particular problem and they worked together to articulate the problem and find the root cause?
This could both fast-track the understanding and the new tests to solve it.
Issue #3: Relying on a Single Source of Data without Immersing Yourself in Different Perspectives
We hinted at this before, but it’s so important to not stick to just a single source of data, as you severely limit your understanding and potential test solutions and ideas.
The more sources you have, the better you can paint a picture of what is happening and why.
Yes, it takes time but conversion rate optimization is all about understanding that audience. Do the work and learn as much as you can.
The more you know the better!
Issue #4: Not Prioritizing Critical Thinking as a Skill
Our brains are weird. We function on a system of base impulses, emotional drivers, and previous experiences. The goal being to keep us alive, procreate and make decisions without wasting too much energy.
Knowing this, it’s always smart for testers (and any business owner) to be aware of the process of both Critical Thinking and Cognitive Biases and how they affect our understanding and decisions…
What Is Critical Thinking?
Critical thinking is the ability to analyze facts and data to form a judgment without bias.
There are hundreds of different things that go into our decision-making, one of which is the bias of decisions based on previous life experiences or situations. We call these cognitive biases.
Those who practice critical thinking understand this, so they use a specific process to help them make unbiased judgments:
- Identification. Find the problem.
- Gather Data. Make sure to use multiple sources. Make sure to not add biases to source selection.
- Analysis. Can you trust these sources? Are they reliable? Is the data set large enough to be true?
- Interpretation + Inference. What patterns can you see from this data? What is it telling you so far? What is the most significant? Are you seeing causation or correlation?
- Explanation. Why do you think this is happening?
- Self Regulation. Do you have any cognitive biases affecting this analysis and test hypotheses? Are you making incorrect assumptions? Work through them to be sure.
- Open-Mindedness, and Problem-solving. With your current understanding, how can you resolve this issue? Do you need to learn more first?
As you can see, having a process to analyze this information is incredibly important. Even then though, you should be looking at any subconscious biases that could be affecting how you are making decisions and analyzing this data.
What Are Cognitive Biases?
Cognitive biases are cheat codes for our brains to save energy on decisions by using pattern recognition. The issue of course is that our biases are not always correct and they can affect our decisions and actions, positively or negatively. Ik This is especially noticeable when it comes to testing.
Here are some examples:
- Action Bias: The tendency to want to take action even when the data suggests no improvement can be made?
- Anchoring Bias: The tendency to base decisions on previously acquired information.
- Authority Bias: The tendency to place a higher value on opinions from positions of authority.
Can you see how these could affect your data analysis and test ideas?
There are far too many of these for me to cover here (some estimate around 150 in total). I highly recommend that you make a list of your own. Then you can try to build in a critical thinking process for analyzing your data as we described before and ‘checklist’ any potential biases that might affect your analysis.
Issue #5: Taking Correlation As Causation
This almost ties back into a cognitive bias, in that we see patterns in data that may exist, but may not be the cause of the result.
They simply occur together often as either a byproduct or a simple coincidence.
For example, most surfers don’t work mid-mornings and will surf instead. (It’s when you have the best offshore wind for the waves).
To the person watching on the beach, you would assume that perhaps these people didn’t have jobs or called in sick. However, after having multiple conversations in the ocean it became clear that almost everyone out there surfing worked for themselves and so can pick and choose their hours.
Now some of them started surfing because they had this flexibility and free time (Correlation), but others chose professions where they could have this flexibility so that they could go surfing (Causation).
Pretty cool, right?
The fact is though, that even after the initial research and ‘interviews’, it would be easy to get an inaccurate view of the data set. Be sure to look at your data with an open mind and dive deeper to find the real cause.
Different Methods of Collecting Qualitative & Quantitative Data
What can we use to collect this data?
For quantitative data collection, we’re usually looking at two types of tools:
- An analytics tool such as Google Analytics or a 3rd party provider to get current results.
- An A/B testing tool such as Convert Experiences so you can measure the numerical change in performance between the variations and the control.
Both of these will give us raw numerical data.
(Check out our comparison guide to A/B testing tools here so you can see which works best for you.)
For qualitative research, we’re looking at a wider selection, as we’re testing multiple different elements:
- Heat mapping
- Click tracking
- Eye tracking
- User recordings
- Onsite surveys, and
- Direct customer surveys.
Eye tracking tends to be the highest cost tool due to its hardware requirements. There are some software options available to install and use in-house, while another option is to hire external companies that set up eye-tracking glasses or cameras to check eye movements and locations of interest.
For heat mapping, click tracking, basic user recording, and surveys you can use a tool like Hotjar that combines all these features. It helps you to spot common issues and get almost immediate insight without having to get 3rd party assistance, and *almost* performs similar functions as eye tracking.
Finally, you can also take user recording a step further and hire agencies who will bring in independent users to use your webpage, get them to perform set tasks, and then record their interactions and pass the information onto you.
TL;DR
If you don’t mind missing out on eye tracking, you can get almost all your data with GA, Convert, and Hotjar.
Sidenote:
Although we didn’t list these in the Quantitative tools section, there is sometimes an overlap where Qualitative tools can be used for Quantitative data acquisition.
You could use a survey tool and measure the replies of X number of participants to get a numerical value of their thoughts on sales copy and how they think they will respond to it.
However… This is still subjective as what people say is not always what they do.
It’s always a good idea to measure their feedback for an action (what they say) and then measure the actual action response also (the action they take). Sometimes this can give you a deeper idea of what to provide and how to frame it.
Learn more about each of these methods for collecting data in this video from Convert’s A/B testing course.
How Do Experimentation Pros Approach Qualitative & Quantitative Data?
Want to know how the pros collect and use data? We recently interviewed 7 CRO professionals as part of our “Think like a CRO pro’ series.
I won’t spoil their interviews as I highly recommend you read them, however, I’ve pulled out some interesting tidbits about how they think about data below, as well as my thoughts on their methods…
Gursimran Gurjal – OptiPhoenix

Quantitative data generally is good to uncover basic conversion holes to understand where users drop, how different channels perform, CR from different devices, where users exit the website, etc, whereas qualitative data helps us uncover details of why users drop or take a certain action.
Combining “Where+Why” along with experimentation paints a complete picture of user behaviour.
Studying qualitative data such as heatmaps, session recordings, survey results, or doing usability testing demands a lot more time to make a statistically significant pattern whereas quantitative data is easier to analyze.When you want to gather more detailed and meaningful insights, it is important to not just rely on GA or Hotjar to collect data but rather push your own custom events to make the data more meaningful such as tagging the recording for all the users who get an error in the checkout process, sending an event into GA for which filter or sorting option is being used the most, etc., so you can make the most of the data available.
Adding custom tags to get a throughline of data is such a fantastic idea. This way you can not only see the issue and where it led, but also where it originated and the traffic source.
Haley Carpenter, Senior CRO Strategy Expert

Constantly remind yourself that we all have biases. Know that it is your job to report as truthfully and accurately as possible. Integrity is a key value to hold high.
Also, double-check your work or have someone else review it if you’re unsure of something. A second pair of eyes can be extremely beneficial sometimes, especially if you’ve been staring at something for hours, days, or weeks.
I once took an anthropology course where we had to transcribe recordings. The professor stressed that it was of the utmost importance to keep the transcriptions true to the person who spoke the words. We were not even to do something as little as cut one two-letter word or correct a small grammatical error.
I’ve held this lesson with me to this day and I apply it to data analysis… especially user testing recordings. It’s important to keep your analysis as true to the original data as possible
Having multiple eyes on research and results is a great way to not miss any issues, remove potential biases, and get different points of view. This can often lead to insights a single tester would have missed.
Rishi Rawat – Frictionless Commerce

My views on quantitative data:
The data is the data. Don’t squint to make sense of it. Don’t be emotionally tied to it. State your hypothesis before the data collection starts. If the data disproves your instincts, redesign a new test and launch it. The data is the data. Respect it.
My views on qualitative data:
We have a controversial take on this topic. We don’t believe in end user research, meaning, I don’t talk to people who bought the product. It’s not that I don’t think this type of research is important, it is; it’s just expensive. I prefer to get all my qualitative data from the founder or inventor of the product I’m working on.
Where the end buyer’s user experience is simply a snapshot of the one purchase that was made in that one moment, the inventor has context about the whole journey. I want to get my quantitative ‘feel’ from the founder.The founder/inventor has so much institutional knowledge it’ll make your head spin. It’s just that they’ve been in the ‘middle’ so long they don’t know where to start. This is where the question-asking skills of the optimizer come into play. The optimizer helps the creator with the outside view. I place a lot of value on this type of qualitative data
Now, this is an interesting idea…
In CRO we tend to focus on the user to understand the customer journey. The issue is customers sometimes don’t know what’s wrong or how to articulate it.
Likewise, however, the business owner can know the product inside out but be poor at communicating it. To them, it’s obvious because they have all the experience, but to the customer, that message can be missing something. In an ideal world, if you’re running tests for another company, you want to speak to both the audience and the owner.
If you’re stuck for time or resources, then speak to the business owner. Like Rishi says, they often have all this insight that can be pulled out. Our job as testers is then to find where that’s missing and how it might connect with the customer.
Sina Fak – Conversion Advocates

The reality is that all data has bias built into it.
Everything from how the data was collected, to the sample data that is used for analysis, to the person reviewing the data and running the analysis – there is an element of bias we cannot fully control.
Data alone won’t give you the whole story. It will only give you a starting point to understand part of the story and draw insights. The only way to treat data in a way that tells an unbiased story is to put it to the test and run an experiment with it
This ties into what we were saying earlier.
Every test and research has bias. We can try to negate some of that with critical thinking and analysis processes, but it can still creep in.
Test the idea, find out and test some more. Don’t forget the scientific method. We can ‘fail forward’ and find the answers we’re looking for also.
Jakub Linowski – GoodUI

In general, the more measures we have that are coherent, the more reliable and trustworthy our experiments can become.
When it comes to comparing A/B test results, there are a few ways we can do so:
● Comparing Multiple Metrics From The Same Experiment (e.g. consistency of effect across adds to cart, sales, revenue, return purchases, etc.)
● Comparing Historical Data Across Separate Experiments (e.g. consistency of effect between two separate experiments ran on 2 separate websites
Don’t forget that Quant and Qual data analysis is equally as important POST TEST as it is in our initial planning.
Having a process in place to checklist through potential issues and locations for ‘aha moment’ can give far better results than an initial glance.
(Sometimes the data is right there and we miss it.)
Eden Bidani – Green Light Copy

I try to work as much as possible with both types of data side-by-side in front of me. For me, that helps balance out the full picture.
The qual data gives depth and meaning to the quant, and the quant data provides the general direction as to which elements of qual data should be given more weight.
Having both data sets together so that you can compare and contrast is the best way to analyze and understand what’s happening.
This ties into what we were saying before about having a single data set to find the issues and solutions. If all we had was one then we would come to different conclusions. Use both to try and find that correlation.
Shiva Manjunath – Speero

The way I try to approach Quant + Qual analysis is like a police interrogation. There is a motive or hypothesis, but you can’t assume the person you brought in for questioning is innocent or guilty. The person brought in (experiment data) is assumed to be innocent, and it is your job to prove them guilty beyond reasonable doubt (statistical significance).
So you can look at the data yourself, interview other people (qualitative data), and perhaps look at bank statements or look at the logs of when someone clocked in/out for work to see if their alibi checks out (quantitative data).
Maybe not the best example, but you have to always approach it objectively. And corroborate data sources (e.g. heatmaps with polls on the site with quantitative data) to come up with a story, and see if that supports, or doesn’t support, the hypothesis. With statistical rigor, obviously!
I love this analogy and it reminds me of Sherlock Holmes and ties right into testing.
I have no data yet. (Or not enough). It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts.
As experimenters, we need to remove all biases. Either experienced or simply because we came up with the hypothesis. Instead, we need to treat the results fairly and find the truth.
Our goal is not to be right. It’s to find what works so we can build on it!
A summary of all the interviews about how experimentation pros handle qualitative and quantitative data can be found in this video.
What Is the Best Way to Use Data to Design Winning Tests?
If you’ve been testing a while then you know that most tests don’t create winners. In fact, only around 3/10 will win, while the others are considered failures.
The terminology of win or fail is not great though. Yes, the test didn’t provide lift, but it does give us data that we can use to improve and find out why.
Remember:
We don’t focus on a single test. Even if it wins, we still use an iterative process of learning and improvements. We test, learn, hypothesize and test again.
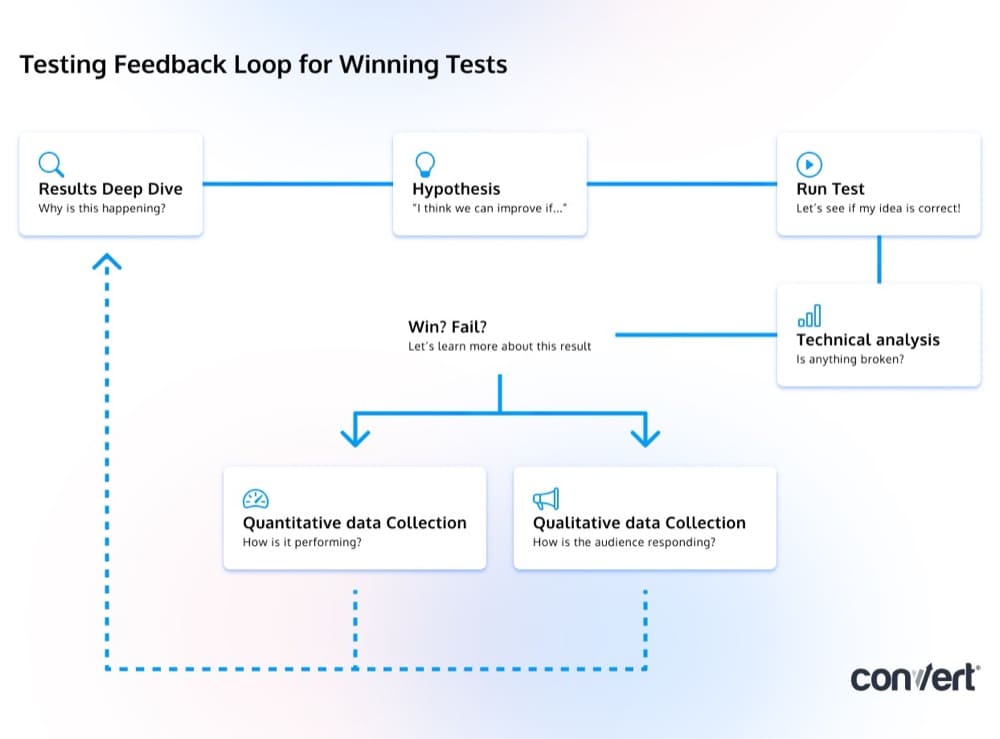
This helps us to create a feedback loop of new data to either support or disprove ideas.
- We test and fail but we learn.
- We take those learnings and test them until we win and get an improvement.
- And then we continue to test until we hit the local maxima and can’t improve any further.
Don’t focus on trying to get a winner right away. This is the fast path to claiming that CRO doesn’t work for you. Instead, turn data into insights and learn more each time.
You might be close to a winner but it just needs better execution.
Or you might be close to an aha moment that can fundamentally change your entire messaging. Stick at it and keep learning with each test!
Build that feedback loop into your data processing and testing process.
But most important? Make sure you can access and understand the data you’re collecting, that you’re using that data correctly and that you can trust it!…
How to Improve Data Accessibility in the Organization
It’s all very well having data to work with, but it’s useless if you can’t access it to learn from!
Some companies will often have a bottleneck in their data flow by only having access to their data via their data scientist. If you need the information then you either need access or to work with them directly, causing issues.
A great way to get past this is to democratize data access:
- Allow data access for traditionally single role tools (GA etc) to the teams that need it,
- Look at using self-service tools that have data reporting capabilities baked into them that the whole team can use,
- Build a centralized learning repository of data results. This allows the entire organization to get data insights, not just the direct testing team.

Why care about data access?
Because access to data increases the number of decisions that can be made that may affect your business’s ROI.
The trick of course is making sure that once you have access, you can find what you want…
How to Improve Data Usability by Collecting Data that Can Be Trusted
Data Usability refers to the ease at which data can be used to answer questions.
If we look at it from an overview, the goal with your data should be:
- To find insights that affect business ROI. Without that, it’s just info data with no goal.
- To find them fast and not have to struggle to get the information.
- And to use those insights to make quick and trusted decisions. Either because the data is trusted or because you understand and are not manipulating results or being fed false positives.
As you can guess, there can be some issues here, depending on the systems and processes that you have in place.
We’ve already discussed how important it is to be able to access that information and the benefits of having tools or processes that have self-service capabilities to open up data reports company-wide.
But now that we have access to that data, we need to make sure that we can both find the information that we want and be able to trust it.
Ideally, you need to be proactively running processes to organize your data sets:
- Make the most important metrics easily findable.
- Use reference models and goals to find specific data sets that traditional tools may not track.
- Ensure synchronization between data sources so updates and edits and new information don’t go missing.
- And allow your data science team to crunch your big data so you can easily find all this information and trust it!
Once you have this end goal in mind for your data, it then becomes easier to start building out preparation processes in advance for new data sets coming in. (It’s much easier to remember to tag specific actions in advance when you know you want to be able to find them later).

How to Conduct Unbiased Data Analysis to Generate Insights that Inform Hypotheses
So how do we use this data to get insights and ideas?
Well, spoiler alert, we’ve actually been covering this all the way through this guide so far.
- Aim to use multiple data sources for a broader picture.
- Try to use unbiased processes to collect that data. Don’t limit to specific demographics or devices if possible.
- Use critical thinking to assess the information.
- Look at cognitive biases and how they may be affecting your analysis.
- Be sure to investigate each data source combined. (Technical, Quantitative, and Qualitative together).
Allow Learning from Tests to Inspire More Tests
You should be treating your tests as a feedback loop for further improvement. This can be on your current test to keep improving and getting more lift, or you can even apply this to older tests where your new insights could help even further.
Either way, the goal should be to test, learn, improve and repeat until you can’t get any more lift.
But… How do we actually go about learning from those test results?
Well, the good news is that we wrote a 7-step guide to learning from your A/B test results that you can check out here.
If you don’t have time right now then here’s a quick recap:
- Start by making sure you can trust your results. Are they accurate? Are they significant? Are you confident in them? Was the test run for long enough? Were there any external factors influencing them?
- Go micro and macro. Just because a test won or failed, you need to see how it affects your guardrail metrics. Ironically, a lift in CTR can mean lower sales if it appeals to the wrong audience. Likewise, a drop in CTR can be a lift in sales, as it may be only appealing to the best audience now. So check your metrics, not just your test results.
- Go deeper and segment your results. Not every audience, traffic channel, and device will perform the same. Some channels may be broken. This can then skew results where it seems good or bad, as you don’t have a detailed picture. (This can also give you insight into variants that will perform best to certain channels, helping you to segment your delivery for a higher lift).
- Check performance and user behavior. Just because we ran a qualitative and quantitative data analysis before, doesn’t mean you should skip it after the test. In fact, this is the best way to understand what happened and how you got these results.
- Learn from the failures. What went wrong? How can you fix this?
- Learn from the winners and improve further. Did you get a new aha moment? Do you have more ideas of how to improve the page again after the QA and Qual analysis? Keep pushing for more lift!
- Don’t forget what you did! Get in the habit of creating and using a learning repository. This way you can see past tests, learn from them, train new staff and even go back and apply new insights to old ideas.
Conclusion
So there you have it. Our entire guide to using technical, quantitative, and qualitative data to create winning tests.
It doesn’t matter if it’s A/B, split URL, or multivariate testing. You can use this same methodology to learn more from every test you run, so go ahead. Run those tests, learn from those mistakes, analyze that data and then let us know how much lift you got!

Written By
Daniel Daines Hutt

Edited By
Carmen Apostu
