Smaller models, smarter prompts, and the lessons learned from “strawberry-gate”
Remember when AI couldn’t count the number of R’s in “strawberry”?

Our collective sneer was deafening. It was also revealing, exposing key insights about our relationship with AI. Some of the reaction was relief that we got to keep our jobs another day, but there was more beneath the surface.
In this article, I’ll explore why this seemingly trivial question is so significant and how it helps us cut through the noise and hype surrounding AI, ultimately leading to practical tactics for smarter and more ethical AI use.
Part one: What’s the problem?
How many ‘R’s?
Now, back to “strawberry-gate”. My reaction to it can be summed up with this comic:

In short, many people misunderstand how LLMs work, thus underestimating their usefulness.
Additionally, to me, “strawberry-gate” also highlighted two distinct modes of thinking: the technologist mode and the practitioner mode of thinking.
Technologists: To be a technologist means having a curiosity about the development and impact of AI, along with a deep interest in the technology’s progress. From this perspective, an LLM’s ability to answer the question is significant.
Practitioners: To be a practitioner means we’re interested in how we can implement AI into our lives, whether personal or professional. To a practitioner, the failure to count letters mattered less. After all, existing tools can accomplish tasks like this. The same applies to other LLM limitations, like math.
We like to believe we’re practitioners—practical thinkers, focused on integrating and utilising AI. However, given the importance of this technology and the fear of being left behind, we can’t help but fall into technologist-like thinking. As a result, we get lost in the noise about AI’s future development potential. Active deception on the part of the tech giants is not helping matters either.
So, how do we prosper despite all this noise? The key piece is understanding how LLMs work (or, more specifically, how they “think”). Let’s briefly take a look at this.
Mind maps and how LLMs “think”
AI is a broad term. What we’re generally discussing here is Generative AI: a type of AI that generates content, such as text, images, music, videos, and code, by learning patterns from existing data. Specifically, we’re referring to Large Language Models (LLMs), which are essentially word prediction and pattern recognition systems.
Geoffrey Hinton, one of the godfathers of AI, was the champion for this pattern-recognition approach. In his words, the goal was to “simulate a network of brain cells on a computer” to figure out how to teach a computer to “learn strengths of connections between the brain cells so that it learned to do complicated things.”
A simple way to think of this is to imagine a mind map of associations.

A mind map begins with a central topic, then branches out to subtopics, and then further into sub-subtopics. In an association mind map, every new connection is based on an association.
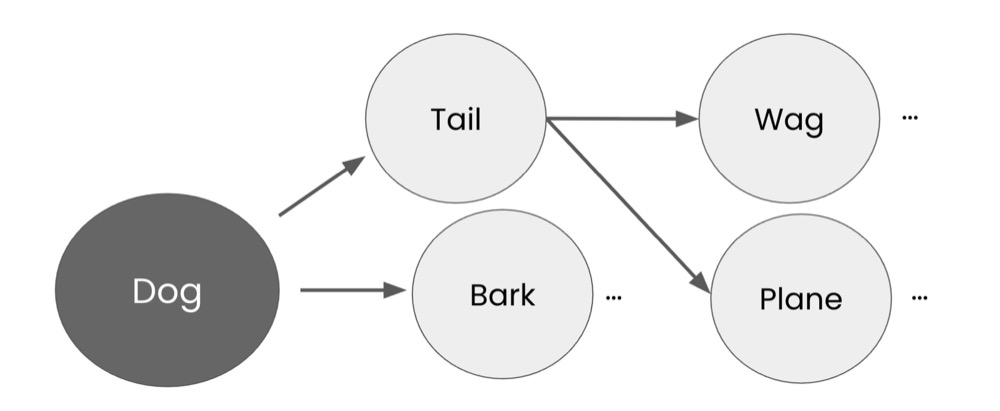
Association mind maps mimic the pattern-matching ability of LLMs. Imagine an LLM creating many of these associations and then using predictions to decide on what words to pick next. Yes, this is a highly simplified view of how LLMs work, but this helps understand them. This also explains why LLMs can’t count or perform math. And why LLMs have no concept of fact or truth.
But what about the advancements in LLMs? Aren’t LLMs improving to the extent that we no longer need to worry about these current limitations? Let’s take a look…
Part two: The illusion of progress
As new models are released almost every other week, we see posts like this:

Let’s put aside the unhealthy worship of tech billionaires and assume that AI is indeed progressing as quickly as suggested here. Let’s acknowledge some uncomfortable truths about the nature of this progress.
The cost of progress
A study from May 2024 detailed that the cost of training models has increased 2.4 times per year since 2016. This cost includes hardware and energy. Each training cycle of the latest and greatest model is equivalent to the power consumption of 120 US homes for a year. This ever-increasing demand for energy is keeping us dependent on fossil fuels.
Worse, many AI data centres require ever-increasing volumes of clean (drinking) water to cool them. The cost of this is not only a permanent removal of drinking water from local supplies, but also pollution to our environment as chemicals are released as a by-product. Poorer, rural areas often bear the brunt of the cost in terms of health, especially in countries in the global South.
There is also a distinct lack of transparency from the tech giants regarding this, with some using shell companies to hide their activities.
All this is based on the assumption that increasing the volume of learning from AI models will suddenly lead to the emergence of consciousness (aka AGI). Does consciousness work like that? And do we want to risk the world to find out?
From an investment perspective, a 2024 Goldman Sachs report detailed how spending on AI is expected to reach $1 trillion, with many investors now concerned about their investments in AI.
I haven’t even touched on bias in training data, and exploitation of labour, etc. I recommend reading Karen Hao’s excellent book, “Empire of AI,” for a more thorough exploration of the cost of AI.
Now, I can hear many asking: Why you being so negative, bro? What about the progress we’ve made and are making with AI?
The complicated view of progress
Let’s begin by discussing how we measure progress.
Circling back to our number of “R’s in strawberry” question. If you ask a recent model this question, they will likely get it right now. But is that proof that an LLM has improved in terms of its reasoning capacity, or is it just that the LLM has “memorised” the answer?
Specifically, if the answer to the “strawberry” question is included in the training data, then the model is likely to have been trained on that answer as well. And even if it hasn’t been trained on that precise example, if training has been done on the reasoning steps to work out the answer, then that really doesn’t demonstrate reasoning capability.
There’s a similar concern about data contamination across the other typical AI benchmarks as well. Putting aside whether the benchmarks themselves accurately determine the progress of the performance of LLMs, the following paper found widespread data contamination issues.
This claim was further explored in Apple’s paper on “The Illusion of Thinking”, which highlighted “a complete accuracy collapse beyond certain complexities” of the newer generation of LLMs: Large Reasoning Models (LRMs).
Additionally, the following paper tested the success rates of real-world tasks and found a success rate of about 30% for AI agents. For a technology touted and hyped to replace teams, that is an astonishingly low success rate.
So, is all progress a lie? Of course not. There is progress in some ways, but there’s also a lot of noise and uncertainty around the reality of this progress.
Okay. This has all been quite negative, and I may have lost many of you. The fact remains that the technology is here, it’s not going away, and there’s a lot we can do with it. The question now is, how do we use it ethically and responsibly to achieve the best results?
Let’s look at some practical tips…
Part three: Practical steps to cut through the noise
My overall approach is straightforward. Use smaller models, utilise existing tools (such as calculators and functions), break down tasks into more manageable steps, and incorporate more human reasoning in our interactions. I’ll unpack these with a series of tips:
Tip 1: Use smaller models
Before using a large reasoning model, consider whether a smaller, more power-efficient model meets your needs. These models tend to have “mini” or “lite” tacked onto their names. You’ll be surprised at how well the smaller models perform and serve their needs.
Additionally, consider running LLMs on your local machine using a tool like LM Studio. For instance, I’ve found “Qwen” to be a highly accurate, small language model well-suited for general tasks. Other small LLMs are also available for functions such as coding. Even if the models aren’t quite perfect for a particular task, they can be fine-tuned quite easily and without much expense.
Now, I know what you’re thinking. What if my needs are more complex? What then? Sure, you could use larger models, but there are ways to use small models to match (and even outperform) the performance of the latest reasoning models. Read on…
Tip 2: Improve your prompting
Chain-of-thought prompting involves encouraging models to break down problems into smaller intermediate reasoning steps before presenting a final answer. This approach to prompting mimics a human-like logical progression of thought.
The following study on chain-of-thought prompting investigated the effectiveness of this approach and found that this technique enhanced the accuracy of smaller models, matching the performance of larger ones. Moreover, since you’re explaining the reasoning steps, this approach provides a greater level of transparency and control of the output, something not often found in larger reasoning models.
Additionally, you can use few-shot prompting. This technique involves providing a few input-output examples (demonstrations) before the actual task query to help the LLM understand the desired format, style, or reasoning process to follow. Refer to this study to understand the positive impact on accuracy when using this technique.
If explaining reasoning steps sounds like too much work to you, you can use AI to help you. Here’s an example of what that could look like in practice:

Take a specific problem (which can be a generative task, like creating an article). Ask the AI to suggest reasoning steps to complete the task or solve the problem. A human should review and refine these reasoning steps, then apply the steps with AI. Finally, a human should review the output before finalising it.
Need help generating examples for few-shot prompting? Here is an example interaction pattern we can use to generate these examples:

We prompt AI for ideas. With the list of ideas, curate them, adding our own and removing ideas we don’t like. Feed the curated list back to AI to generate more examples. Continue this cycle and you should find you get higher quality ideas, closer to your requirements.
You’ll notice that both interaction patterns above incorporate more human involvement. That’s a good thing. It means we’re using AI to enhance, not replace us. Add a step for reflection, and we also learn as we interact, meaning we need to use less AI for similar tasks in the future!
But wait. If you use the same pattern on a larger model, can’t you get even better results? In my testing, not really. Plus, I’ve found the larger models to be slow and verbose for this sort of multi-step interaction flow.
Tip 3: Self-reflection
Self-reflection or “self-critiquing” is the process of an LLM checking either its output or the output of a different model. Self-reflection has been shown to improve the quality of output by 20%.
There are some key things to consider when doing this. While self-reflection can be as simple as prompting something like, “Review your output and see if you can do better”. In practice, this works only some of the time. As the paper referenced above notes, it’s better to give the LLM some feedback.
This can be either feedback from a human or from an LLM using a framework to provide critique itself. For example:
Prompt: “Critique my hypothesis: Blue buttons are great because the sky is also blue.” Use the following criteria:
Problem: Identify the specific issue being addressed by the hypothesis.
Proposal: Describe the proposed change.
Expectation: The measurable changes that are expected.
Reasoning: Supporting data and reasoning methods used.”
Alternatively, if we test the outputs of our prompts and identify weaknesses, we can provide the LLM with guidance on how to work around these weaknesses to improve the output.
Tip 4: Break things into atomic parts and use tools
In “Atomic Human,” Neil Lawrence outlines the key differences in intelligence between humans and AI. Namely, that AI is like an ant colony, comprising many simple intelligences, each with distinct roles. When viewed from afar, these intelligences give the impression of high intelligence, but this view is based on the colony as a whole.
What that means in practice is to understand that at a simple interaction level, LLMs are not very smart. So break down a complex ask into smaller, more straightforward prompts.
For example, suppose you have a CSV file containing the results of an A/B test. The CSV includes data for multiple metrics, along with their respective significance levels. Instead of loading the entire dataset and asking the LLM for insights, consider breaking the task down into smaller steps. We can even go further by identifying the right tool for each task, such as:
- Determine the rules for “significance” (human-centric)
- For each metric, check if the metric is significant (AI-centric)
- For all significant metrics, summarise insights (AI-centric)
- Review the insights and decide on the outcomes (human-centric)
The above is just one example of how you can break down a task. If you’re unsure how to break a task down, think in terms of what you want to validate and use to guide the task breakdown.

The process breaks down like this:
- Take a simple prompt and AI output.
- Ask: What do I want to validate to make sure the final output is valid? Additionally, is there a tool that can give me a stable answer for a specific part?
- Split the task to ensure that validation happens or that a tool can be used.
- Repeat.
Breaking a prompt down into smaller steps provides a greater sense of confidence in the output, as we’re able to control and validate the output better. We can use the same process to create automated workflows, utilising LLMs to make many simpler decisions rather than fewer complex ones.
Tip 5: Integrate existing tools into your AI workflows
Remember the mind map exercise earlier? It taught us that LLMs are excellent at pattern matching at an incredible scale, but not necessarily best-suited for other tasks.
For instance, there are statistics calculators, geographic and weather information services available as API calls, and so on. We can also create simple tools with Python or JavaScript for AI to access—LLMs can help us build and connect to those tools.
Tools have the advantage of stability. They give consistent answers to consistent questions every time, where LLMs may not.
Many chat tools now allow us to add tools to use. Additionally, if we learn how to use workflow-creation tools like n8n, we can chain together our own bespoke, robust workflows, incorporating tools and small LLMs.
Creating our workflows means we generate output on our terms. This is a huge topic, but introducing the ideas here is a stepping stone to creating our own bespoke LRMs!
Final(ish) words
Gary Marcus, a foundational voice in AI research, was recently asked what he thought about the idea of AI replacing entire teams. His reply was sobering:
“They’re [LLMs] not actually that smart. And putting a not-smart-system in charge of things is not itself a smart thing to do.”
Generative AI (and LLMs) may not be a new technology, but their widespread adoption is new. Seeing them in action feels like we’re witnessing magic. And so we’re tempted with the promise of what they can do for us. The reality is often different.
Ultimately, LLMs and other generative AI are tools. And, like any tool, we need to invest time and effort to learn how to use them properly.
Newer models may promise less of our time and effort. But these models don’t necessarily deliver on this promise in a meaningful way. Besides, we haven’t fully explored the applications of yesterday’s technology. Yesterday’s models may not be able to count, but as practitioners, we should be asking ourselves: “Was asking AI the smartest way to get this task done?”
Going with smaller models is not just about sustainability. We’ve seen how leaner models can often outperform bloated counterparts, especially if we choose a multi-step, multiple interaction approach to working with them. Combine all this with smarter prompting, and we have a way to amplify our thinking, not replace it.

The strawberry incident wasn’t just about counting – it was a litmus test for understanding AI’s fundamental nature. Hopefully, we now know that it wasn’t AI that was put to the test. We were.


Written By
Iqbal Ali
Edited By
Carmen Apostu
