Local LLMs Part 1: Exploring the World of Small Language Models
What do we want from AI?
I want it to be accurate and practical for the tasks I need them to perform. And AI certainly achieves that for the most part.
But peel back a layer and there’s a whole bunch of stuff that suddenly becomes really important.
Security and privacy, for instance. I don’t know about you, but I don’t trust these big corporations with my data. And neither should you. [1, 2, 3]
And then there’s also the matter of sustainability, because I don’t know if you know, but the energy requirements for training one of those large models are immense. [1, 2, 3]
You could see the release of ChatGPT in 2022 as merely good PR for Machine Learning (ML), which has been around for years. (Machine Learning is a process of training models to do specific tasks well.)
It may be time for us to take a step back from the large LLMs that corporations often push on us, and instead consider smaller models we can run locally on our machines, at least for specialised tasks.
Note: I’ll be using the terms small and local interchangeably.
This isn’t really as difficult as you might think, especially with tools like LM Studio, which I’ll be exploring with you today.
Download and Set Up LM Studio
Head over to lmstudio.ai and you’ll come to this page:
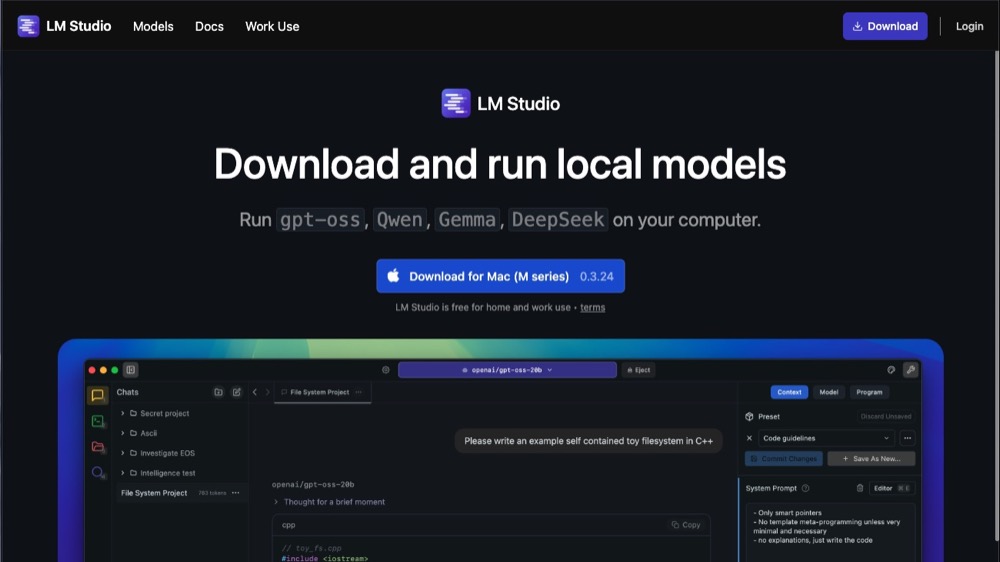
LM Studio’s headline—“Download and run local models”—sums it up nicely. It automatically recognises your machine and helps you pick a compatible model. This level of relevance will be a recurring pattern going forward.
On first run, you’ll be asked to download a model before you get started. It doesn’t matter which one you pick for now.
After installation, you’ll see a fairly familiar chat layout: a chat box and response area. One of the key differences from a normal AI chatbot is that you have to select a model. On the left sidebar, you’ll see Chat, Developer Mode, My Models, and Discover:
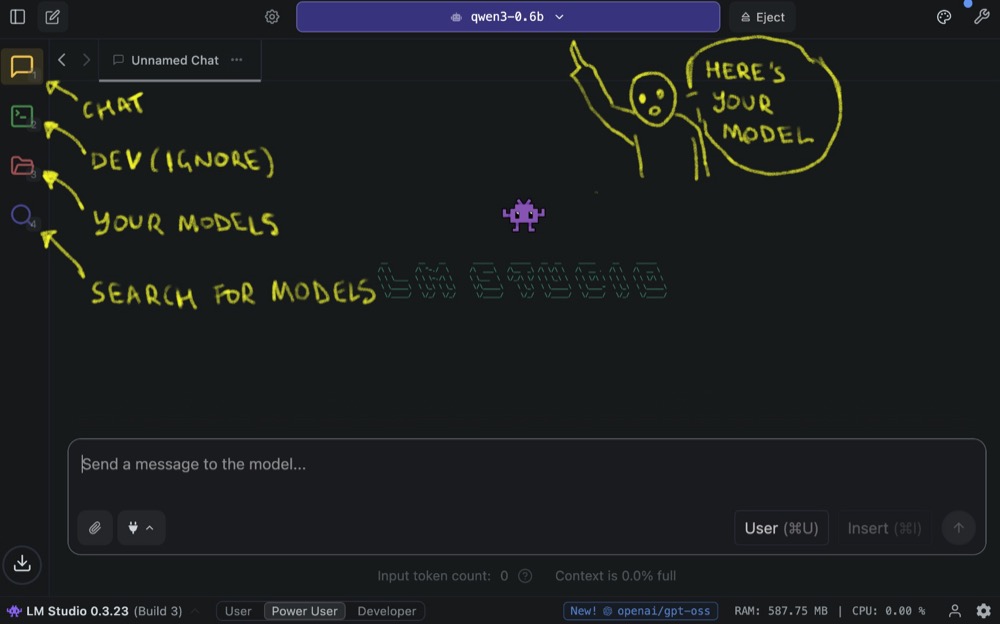
Now, let’s start exploring models! When you first visit the Discover screen, it can be a little bit overwhelming, but don’t worry, we’ll go through this one step at a time.
Hardware to Run Your LMs
In Discover, start with the Hardware section. This screen gives you a good summary of what your hardware is:
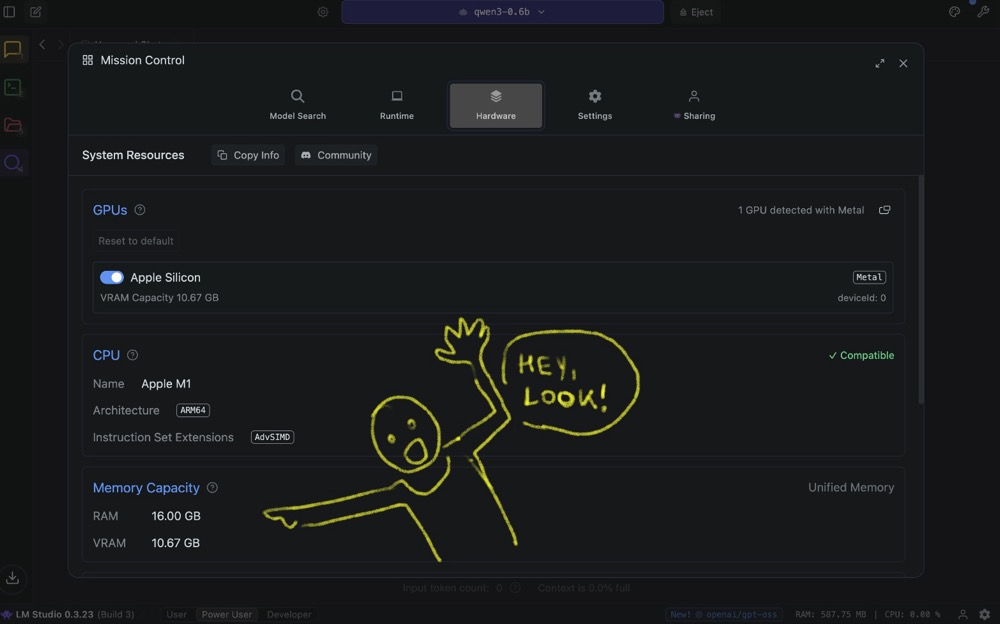
For reference, I’ve got an Apple M Series M1 chip with 16 GB RAM. LM Studio also detects one GPU. That’s key, because LLMs need GPUs (with a lot of RAM) to run effectively. You can run them on CPU, but they’ll be painfully slow.
Side note: The Apple M series is a pretty decent machine to get started with, because they have what’s called “unified memory”, which means that your system memory and your GPU memory are shared, giving the GPU 16 GB RAM available to it.
I’d say you need a minimum of 16 GB RAM to get going (assuming you have a Mac M series machine). Just know that if this is something you want to do more of going forward, you might need to upgrade your machine, depending on the model and use case.
Discovering Models
In the Model Search section, you’ll see a whole list of models available to download. LM Studio shows Best match at the top because it considers your hardware and then identifies the best models you can run on it.
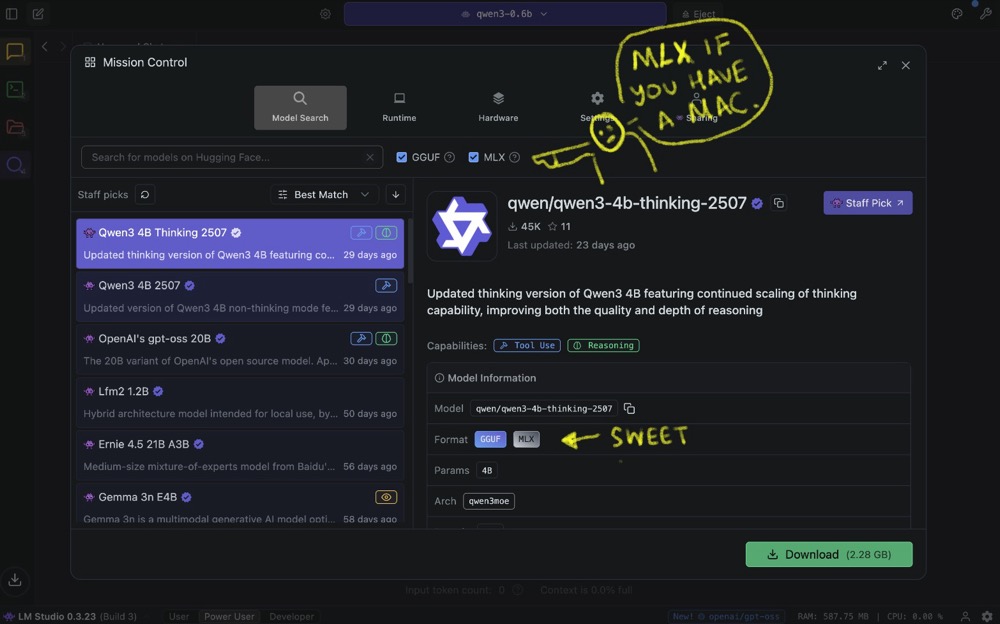
When browsing through models, pay attention to:
- Capabilities: Check what the model is trained for and how it behaves. For me, the Qwen series of models is a good match. It’s being trained for Tool Use, and it’s a Reasoning model. If you use DeepSeek, for instance, it has this lengthy thinking cycle before it responds. This is what “reasoning” or “thinking” is.
- Format: This is important because local models are “quantised”—squished and put in a format that can be effectively used for various machines.
- GGUF is a good format, highly optimised to run on local machines.
- MLX means the model is specifically optimised to run on Apple’s M series of machines.
On Apple Silicon, these two format models are going to be prioritised over all of the other models because they run best.
- Params: Think of parameters as dials that you can use to change the way that the LLM works. So, 4 billion parameters means you’ve got 4 billion dials to tweak the LLM in different ways. To give you some context, ChatGPT 3 had 175 billion parameters. ChatGPT 4 had something like 500 billion parameters. These big models have loads of parameters; the smaller models have fewer, which is partly why they’re smaller.
- Model size & offload: This is another part to pay attention to. For example, 2.28 GB might show “full GPU offload possible”. That means that the model can fit comfortably in available RAM, which can speed up inference.
Our Task: What We’re Trying to Do
We’re going to test these small local models on a real task.
We’ve got loads of user feedback and want to analyse it for insights. We’re not happy with sending this data to a hosted service, so we’re trying to determine if a small LLM can match the quality of insights from larger models.
Here’s our test case, a particularly gnarly example of user input:
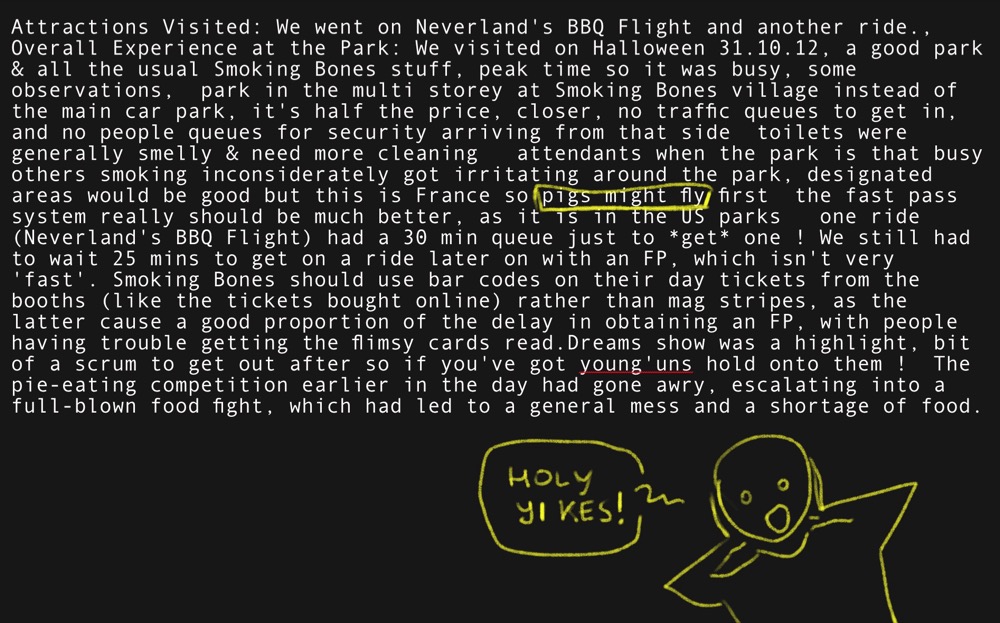
Full text (if you’re a masochist):
Attractions Visited: We went on Neverland’s BBQ Flight and another ride., Overall Experience at the Park: We visited on Halloween 31.10.12, a good park & all the usual Smoking Bones stuff, peak time so it was busy, some observations, park in the multi storey at Smoking Bones village instead of the main car park, it’s half the price, closer, no traffic queues to get in, and no people queues for security arriving from that side toilets were generally smelly & need more cleaning attendants when the park is that busy others smoking inconsiderately got irritating around the park, designated areas would be good but this is France so pigs might fly first the fast pass system really should be much better, as it is in the US parks one ride (Neverland’s BBQ Flight) had a 30 min queue just to *get* one ! We still had to wait 25 mins to get on a ride later on with an FP, which isn’t very ‘fast’. Smoking Bones should use bar codes on their day tickets from the booths (like the tickets bought online) rather than mag stripes, as the latter cause a good proportion of the delay in obtaining an FP, with people having trouble getting the flimsy cards read.Dreams show was a highlight, bit of a scrum to get out after so if you’ve got young’uns hold onto them ! The pie-eating competition earlier in the day had gone awry, escalating into a full-blown food fight, which had led to a general mess and a shortage of food.
The reason this is gnarly is that it jumps around from subject to subject and uses a colloquialism (“pigs might fly”). This might be useful to see how well the model is able to parse that and not take it too literally.
The Prompt We’re Testing
Here’s my prompt:
%CONTEXT:%
Smoking Bones Land is a series of BBQ-themed theme parks. There are rides, shows, and they have a cinematic universe. There are three locations: France, Hong Kong, and California.
%YOUR ROLE:%
You are a customer service support analyst. Your aim is to identify specific problems that users are facing, so that you can improve the product and service. Ignore everything else.
%YOUR TASK:%
Identify only the specific points that are useful to a developer, product owner and support analyst. output in JSON format as defined.
%USER INPUT:
```
I went on the roller coaster, the water slide, and the carousel. We visited in early October, which is off-season. We didn't wait more than 10 minutes for any attractions. If you can try to purchase and print your tickets online in advance, the tickets are about $20 cheaper than the gate prices. Only issue was a pie-eating competition devolved to a full-blown food fight and this caused a shortage of food in restaurants.
```
%SPECIFIC POINTS:%
```json
[{
"specific_point": "Waited no more than ten minutes for roller coaster, water slide, and carousel.",
"sentiment": "Positive",
"tags": ["rides", "wait_times"]
},{
"specific_point": "Food fight from pie-eating competition caused food shortage.",
"sentiment": "Negative",
"tags": ["food", "food_shortage"]
}]
```
%USER INPUT:%
Attractions Visited: We went on Neverland's BBQ Flight and another ride., Overall Experience at the Park: We visited on Halloween 31.10.12, a good park & all the usual Smoking Bones stuff, peak time so it was busy, some observations, park in the multi storey at Smoking Bones village instead of the main car park, it's half the price, closer, no traffic queues to get in, and no people queues for security arriving from that side toilets were generally smelly & need more cleaning attendants when the park is that busy others smoking inconsiderately got irritating around the park, designated areas would be good but this is France so pigs might fly first the fast pass system really should be much better, as it is in the US parks one ride (Neverland's BBQ Flight) had a 30 min queue just to *get* one ! We still had to wait 25 mins to get on a ride later on with an FP, which isn't very 'fast'. Smoking Bones should use bar codes on their day tickets from the booths (like the tickets bought online) rather than mag stripes, as the latter cause a good proportion of the delay in obtaining an FP, with people having trouble getting the flimsy cards read.Dreams show was a highlight, bit of a scrum to get out after so if you've got young'uns hold onto them ! The pie-eating competition earlier in the day had gone awry, escalating into a full-blown food fight, which had led to a general mess and a shortage of food.
%SPECIFIC POINTS:%
```
I’ve got some context about a fictional theme park, I’ve given the AI a role as a customer support analyst, and a task to extract insights in JSON format. This is called a one-shot prompt, where I’ve given it a user input and one specific example as output.
Determine the “Perfect” Output
Before comparing models, I created what I see to be a perfect output for this prompt. There’s no right or wrong answer, but this gives an idea of what I’d be happy with: five insights that capture the main issues from the messy feedback.
%PERFECT OUTPUT%
```
[
{
"specific_point": "Toilets were smelly and need more cleaning attendants during busy times.",
"sentiment": "Negative",
"tags": ["cleanliness", "restrooms", "staffing"]
},
{
"specific_point": "Inconsiderate smoking around the park; suggests designated smoking areas.",
"sentiment": "Negative",
"tags": ["smoking", "guest_behavior", "suggestion"]
},
{
"specific_point": "Fast pass system inefficient; 30-minute queue to obtain one and still big wait times with fast pass. Suggests because of flimsy mag stripe ticket machines.",
"sentiment": "Negative",
"tags": ["fast_pass", "queues", "system_issue"]
},
{
"specific_point": "Dreams show was a highlight, but exiting afterward was chaotic and crowded.",
"sentiment": "Negative",
"tags": ["shows", "experience", "crowding"]
},
{
"specific_point": "Pie-eating competition escalated into a food fight, causing general mess and food shortage.",
"sentiment": "Negative",
"tags": ["event_issue", "cleanliness", "food_shortage"]
}
]
```
You can use ChatGPT to draft a first pass and then edit the output until you get something close to perfect. I always start with an AI-based output and then tweak it to make it the best that it can be.
Evaluating the Models
Establishing a Baseline with ChatGPT
First, copy the prompt and run it in ChatGPT. This gives us something to compare to when we look at LM Studio.
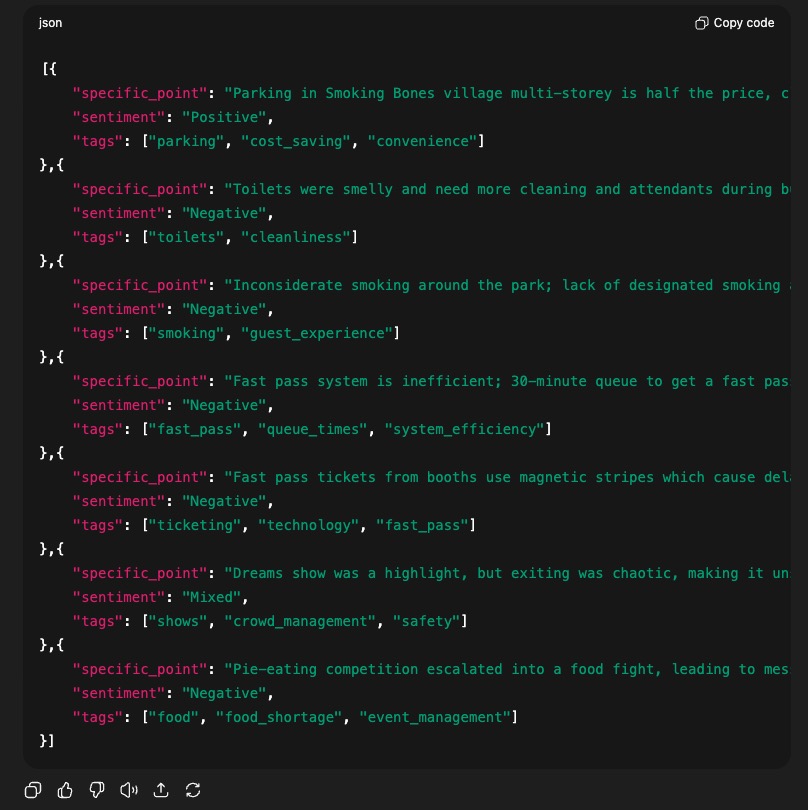
In my test, ChatGPT found seven specific points, and they’re not bad. It’s picked up a couple of other things that I didn’t pick up. Adequate, though not perfect.
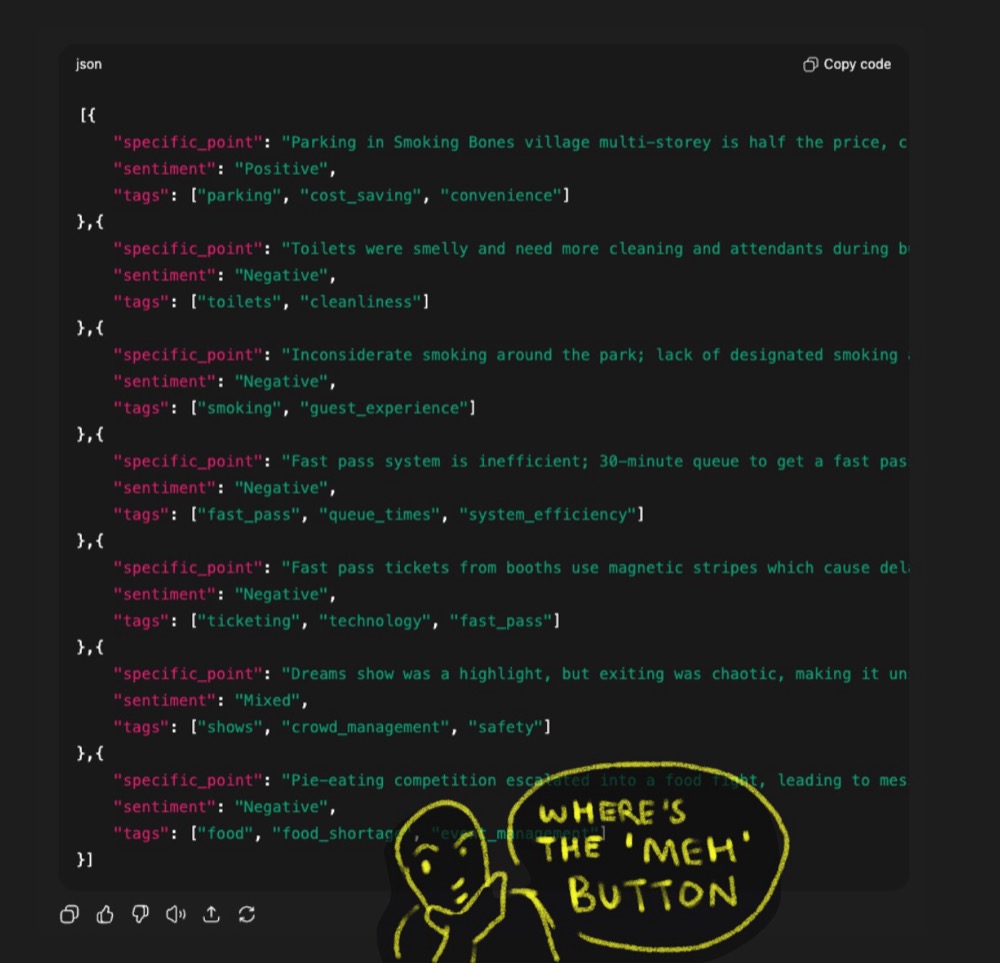
Testing the Smallest Model vs ChatGPT
Now, let’s head back to LM Studio and start with the 0.6 billion parameter model to see what we get.
Right away, we see it doing some thinking. It only found two points, which isn’t great:
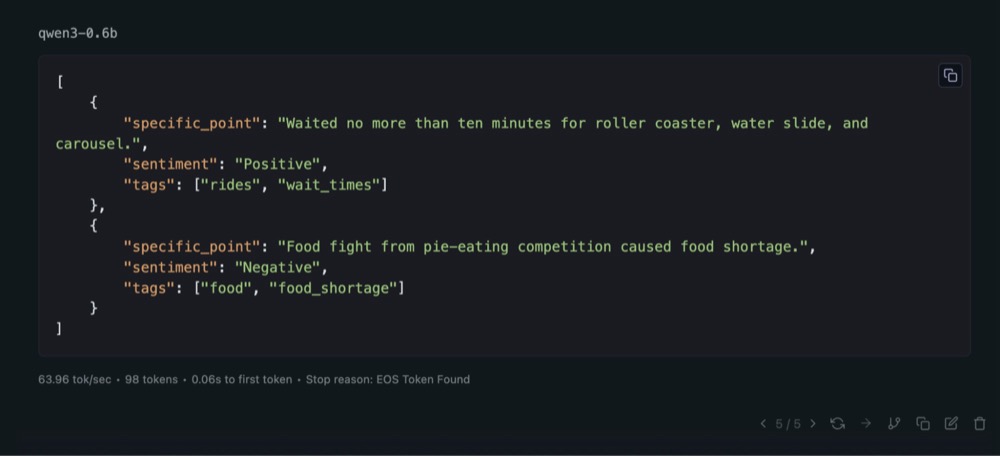
Edit the last output type in “no_think”, save, and generate again. You’ll see it generate the output straight away. And that is very quick. 63 tokens per second.
But the output is not great.
Testing a Slightly Larger Model
Let’s try the 1.7 billion parameter model. When you load it, it’s going to move to memory. Click “use current model”, then delete the previous output, and start again.
This one has a “think” toggle—disable that and trigger again.
In my test, it found eight insights, which is closer to ChatGPT’s performance. So, this is comparing a tiny model to a squillion-parameter model, ChatGPT 5. And the insights are almost on par with ChatGPT:
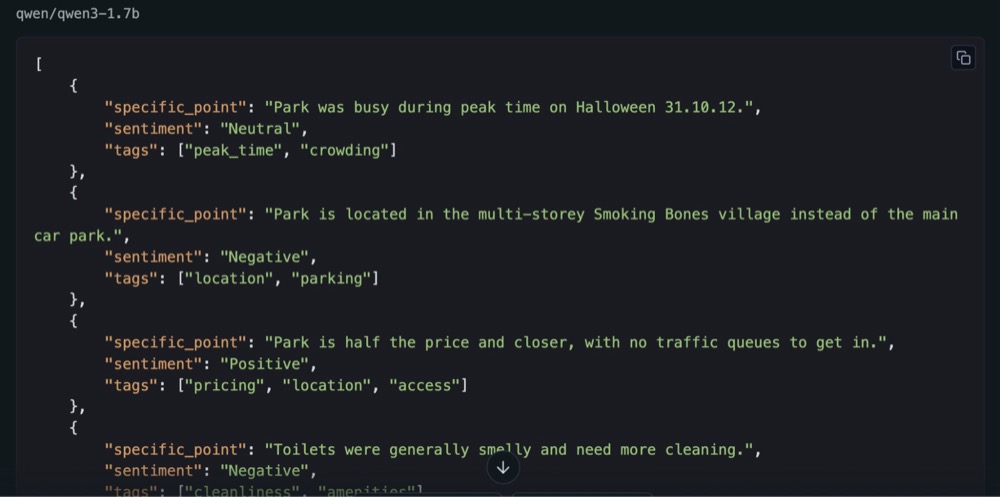
What All This Means
As you’ve seen, working with small models is easy, especially with LM Studio. It’s also really addictive, and it can lead to some great finds. That 1.7 billion parameter model, I think, is a great find.
But I reckon I can squeeze more juice out of the 0.6 billion parameter model. In my next blog post, I’m going to train that 0.6 billion parameter model to improve its behaviour and try some prompting techniques to get better output.
It’s now up to you to explore the world of small models and find one that suits your use case. Have fun exploring.
Editor’s note: This is the first in our series on running AI locally. If you want to keep going, we’d recommend checking out how we beat ChatGPT 5 with a tiny model, set up a local LLM server, and built a personal chat interface. You might also enjoy our piece on smaller models and the lessons from “strawberry-gate”.


Written By
Iqbal Ali
Edited By
Carmen Apostu
