AI Hallucinations. Why AI Lies and How to Keep It Honest
Is this our future?

Not only are we as individuals becoming more reliant on AI, but we’re also seeing numerous AI Agents coming online. AI Agents are entire workflows and “teams” of AI working together to bring us content, provide customer “support”, manage our medical reports, and more.
A recent Cloudera report, which surveyed over 1,400 enterprise IT leaders, found that 57% of companies had started implementing AI Agents within the last two years. 21% of those did so in the previous year alone. This indicates an accelerating shift in the landscape of AI-based.
But there’s the problem. Because lurking inside every one of those agents (and every one of our AI chat interactions) is a gremlin threatening to undermine trust in all of those outputs and systems. The gremlin in the system is AI hallucinations.
Here are some stats to prove the extent of this damage:
- $67.4 billion was lost globally in 2024 due to hallucinated AI output, affecting multiple industries. (McKinsey, 2025)
- 12,842 AI-generated articles were removed in Q1 2025 due to fabricated or false information. (Content Authenticity Coalition)
- 47% of enterprise AI users made at least one major decision based on hallucinated content (Deloitte Global Survey, 2025).
Scary, right? These stats are referenced in multiple places online (some viewed as “credible” by ChatGPT). They’re also likely hallucinations themselves—try to find a primary source for those stats and you’ll see. Yet all this does is further prove the expansive problem of AI hallucinations.
Wait, what are AI hallucinations anyway?
What are AI hallucinations?
AI hallucinations occur when an artificial intelligence system generates information that is fabricated, incorrect, or not grounded in its training data. These hallucinations are often presented as if they were factual, doing so with an unnerving degree of confidence.
The impact of hallucinations can be enormous. They contaminate data analysis, disseminate falsehoods, and compromise decision-making. Worse still, in automated systems like agents, minor fractures in accuracy can amplify into gaping chasms of wild fabrication. Bottom line: understanding AI hallucinations is crucial because only by comprehending the problem can we create effective safeguards.
My hope in this article is to explain how and why AI hallucinations occur and provide you with tips and techniques to manage them effectively, regardless of how you use AI.
Part one: What are AI hallucinations?
We’ve covered a vague definition of AI hallucinations earlier, but “AI hallucinations” is kind of a catch-all term, so let’s get specific and break this down in terms of types of errors. Here are some key types of errors:
- Factual errors are when AI makes straightforward errors in objective facts.
Example: Paris is the capital of France, not Berlin. - Faithfulness errors are when AI responses misrepresent information.
Example: A user says, “My child broke the product in two weeks,” and the AI categorises this comment as “Product quality complaint”—the user technically didn’t complain. - Logic and reasoning errors are when AI makes invalid inferences or deductions that contradict principles of sound reasoning, all while remaining true to the source material.
Example: A research paper might mention “coffee is a stimulant” and “sleep deprivation affects cognition,” and AI incorrectly assumes that “the paper demonstrates caffeine causes sleep deprivation.” The facts are preserved, but the AI falsely claims the paper made a connection. - Unfounded fabrications are when AI outright fabricates facts or data.
Example: AI fabricates a series of books about “Percy Nutter,” written by J.K. Rowling.
This list is far from exhaustive. However, it shows how AI hallucinations can be categorised into distinct types of errors. Categorising errors in this way provides a more precise and useful way of examining AI hallucinations, especially when we want to develop safeguards.
What causes these errors?
But wait. Why do these errors occur in the first place? And isn’t this a problem that will simply disappear as technology advances? To answer that, let’s take a closer look at how LLMs work and how these types of errors occur. Here’s a breakdown of some key points:
LLMs are probabilistic by nature
LLM models use the context of our prompts to build up a sort of “associations map” based on their knowledge base. Think of an association map like a mind map, where each word is placed along with its context at the centre of the map.
Note: In reality, LLMs use vector representations and attention mechanisms across neural networks to establish relationships between tokens. But for the sake of simplicity, let’s go with the metaphor of mind map-style association maps.
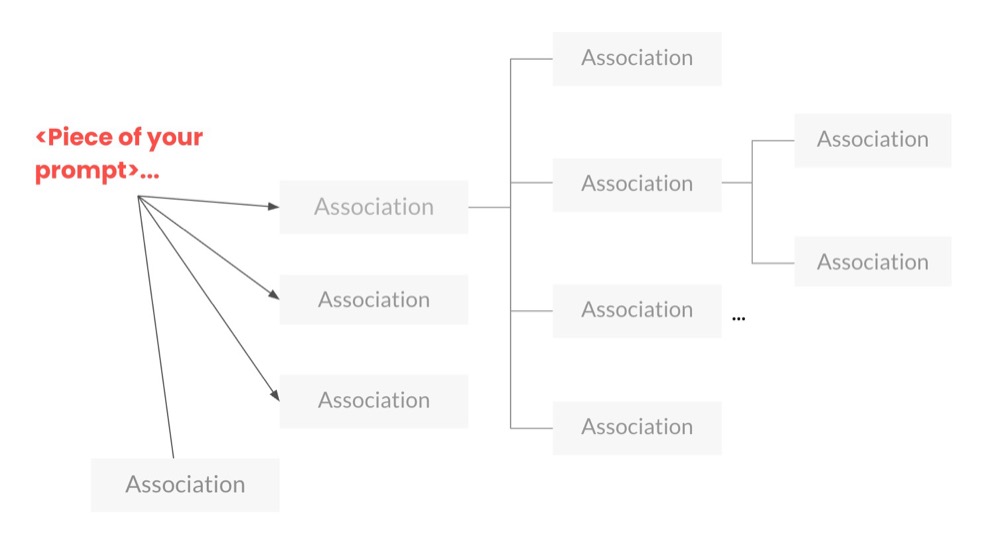
LLMs then use these association maps, choosing the “best” associations based on the input prompt text. This happens repeatedly in a probabilistic manner, meaning that the LLM determines the most likely connection to make.

Some of these connections are explicit in the data. For example, suppose we prompt “What is the capital of France?”, and the LLM has been trained on multiple documents stating that the “capital of France is Paris.” In that case, Paris has a higher probability of being chosen than, say, Berlin.
The probability scores drive an LLM’s choices. Notice how there is no concept of “fact” or “reasoning.” All those complaints about AI not being able to count the number of R’s in strawberry miss the point. That’s just not how LLMs work.

Let’s take things further with a more complex example. We have a statement from a user: “My child broke the product in two weeks”. And we want the LLM to categorise this statement with a label. Now, suppose the LLM wasn’t trained on data where a connection between the specific statement and label was made. In this case, the LLM will establish an implicit connection. The goal is to be “faithful” to the user statement.
Being able to handle requests like this is what makes LLMs so powerful. And that is entirely due to how they operate. Unfortunately, this is also what makes LLMs prone to hallucinations, as it makes “imperfect” probabilistic determinations based on their “associations map”.
Data limitations impact LLM accuracy
We mentioned earlier that LLMs don’t have a concept of “reason” or “fact”. However, they give the illusion of reasoning. This is primarily due to the underlying data on which the LLM was trained.
We’ve all heard the adage: garbage in, garbage out.
More specifically, it’s a matter of “relevance”. Going back to our earlier example, if none of the data mentioned Paris as the capital of France (i.e., there is no explicit reference to this), then the LLM would have to make an implicit association. This can lead to “fact-based” errors. Worse, if the data is completely devoid of mentioning France and Paris, then that could lead the LLM to make unfounded fabrications.
To summarise, high accuracy in LLM responses requires the model to have been trained on “relevant” data.
Imperfect optimisation of the models can impact accuracy
LLMs process text, and so they are trained to understand the relationships between words. The attention mechanism is crucial to how LLMs handle relationships.
Think of attention as a spotlight that the model shines on different parts of the input text to determine which words or phrases are most important for generating responses. The attention mechanism enables the model to focus on the most relevant information, allowing it to identify patterns, understand context, and generate a coherent response.
What this means is that even with relevant and comprehensive training data, errors can still arise due to the way the model’s attention has been optimised. Suboptimal weighting of the attention mechanism could lead to an overemphasis on irrelevant words. If the training data is biased, the attention mechanism could amplify these biases. Additionally, inconsistent attention across words from the input or training data could also lead to errors.

The point is, even with the presence of perfect and relevant training data, the model architecture itself causes differences in behaviour across models. This is why different models have different “characteristics”.
Human biases
Finally, it’s important to note that human biases can contribute to or exacerbate hallucinations. Specifically, the way we interact with and interpret the output of LLMs can cause hallucinations.
For example, asking a loaded question can affect the LLM’s attention mechanism, leading to faithfulness or reasoning-based errors. Similarly, highly confident-sounding claims in prompts can also cause errors. Confirmation bias or other types of bias can lead to favouring output that confirms held beliefs and impede critical thinking.

Let’s also not forget that the training data itself can also contain biases.
Additionally, an over-reliance on AI can also lead to a sense of “laziness” as we rely on AI to do more than it should. Most workflows should involve human-AI interactions, and so we mustn’t overlook the human aspect of the equation.
It’s worth adding that although this article focuses on understanding and managing hallucinations, they’re not inherently bad. In fact, they are extremely useful in some contexts, as we’ve seen. The problem is when accuracy is important. When this is the case, it’s important to manage hallucinations, starting with understanding which aspect of the interaction is failing.
Part two: Measuring AI hallucinations
I’d like to share another set of statistics that’s circulating…
The rate of improvement is accelerating: hallucinations dropped by 32% in 2023, 58% in 2024, and 64% in 2025.
These are another set of statistics where the primary source is difficult to pin down. The data is likely based on Vectara’s hallucination leaderboard, which uses Vectara’s hallucination detection model called the Hughes Hallucination Evaluation Model (HHEM) to evaluate hallucinations across models.
This leaderboard suggests that AI hallucinations are in decline. However, Vectara themselves highlight the limitations of their model—for one, the HHEM mainly focuses on summarisation tasks.
There are still other stats indicating that AI hallucinations are in fact on the rise. This appears to be partly based on the new wave of “reasoning” models, which break down tasks into steps. One possible reason for this is the danger I highlighted about compounding fractures, where a minor inaccuracy in a single step is amplified in subsequent steps.
The key point to make is that identifying and measuring AI hallucinations in a general way can be difficult. It’s therefore important that we understand how the relevant types of errors can be measured in our own applications and workflows.
Ways to catch AI hallucinations
Let’s take a look at some ways to identify AI hallucinations.
Human evaluation
This is where humans assess accuracy. The task involves comparing AI output to a grounded source of truth or the view of an established expert. Having a defined process or protocol can help keep things objective and unbiased.
The primary issue with this approach is the resource investment that’s required. We can address this by limiting evaluations to random spot checks and making projections of the hallucination rates based on these spot checks.
Automated evaluations
The above human evaluation methods can also be automated using bespoke systems. This works especially well when there is an established grounded source of truth, or a defined process for determining “accuracy”—more on this later, when we look at validation interaction patterns.
The hybrid approach
Overall, the most effective way to measure and determine accuracy is to employ a hybrid approach, where automated systems perform most of the detection work and humans evaluate accuracy in areas that are difficult to automate. This can also involve spot checks of the system to audit efficacy.
The importance of transparency
For any of these methods to be effective, we need to ensure that our systems are transparent.
Just like a maths student should show how they derived an answer, so should an agentic system make transparent how it decided on the final output. Even if it’s just you interacting with AI, breaking down a task into steps can help you evaluate and gain confidence in the AI’s output. It can also help in debugging how hallucinations occur.
Again, this is why rethinking hallucinations in terms of types of errors is useful. It leads us to think like a developer. When debugging code, transparency is a critical step in not just determining when errors occur but also in determining how they occurred in the first place.
I’ll admit that I’ve covered this topic somewhat broadly here, so please let me know if you’d like me to elaborate on it in further detail.
Part three: Managing AI hallucinations
Finally, let’s look at four practical hacks or techniques to manage hallucinations in our workflows and interactions.
Full transparency: while I’ve applied some of these methods to my text-mining and user research tool Ressada, others are methods I’m still implementing. These are brief overviews, but I plan to explore them in greater detail in future articles.
Quick note about Interaction Patterns
Many of the following techniques involve specific “Interaction Patterns”—i.e., structured sequences of exchanges with AI. I covered this topic in my earlier article on the subject.
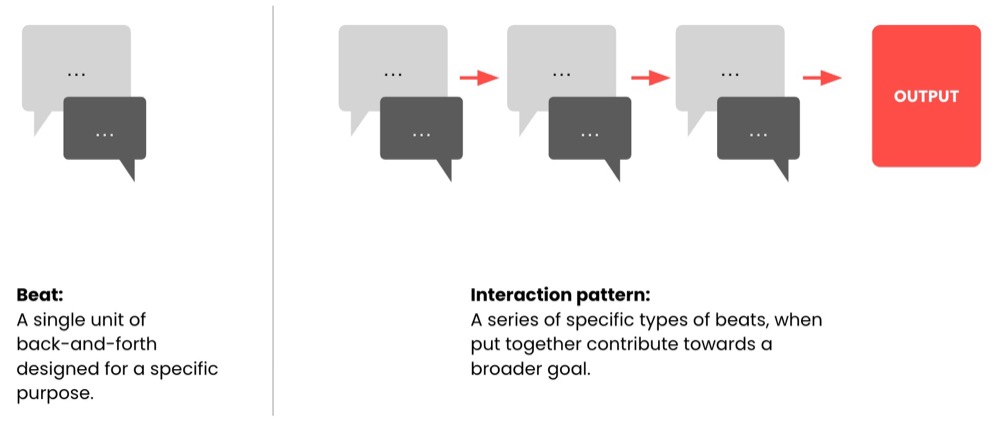
Here’s a brief overview: A beat is when we prompt AI, and it replies. It’s single back and forth. We can describe each beat in terms of its purpose (for example, a simple query). When the output of each beat is fed into the next, the beats build upon each other to create a meaningful output.
Designing a sequence of beats as an “Interaction Pattern” for sharing and reuse is a much more powerful way of sharing AI knowledge with teams than the sharing of prompts.
That being said, let’s go over some tips for managing hallucinations.
Hack 1: Think ahead. Validation-based interaction pattern
Before interacting with AI, we need to ask ourselves: How important is accuracy in our requirement? Because when we prompt, AI will definitely reply. And it may reply with a confidence and swagger that’s persuasive. We need to determine whether that’s the confidence of an intelligence that knows what it’s talking about, or the swagger of a con artist. If accuracy is important, we need to know how we’ll validate the accuracy of what AI tells us.
In short, we need to develop an effective “Validation Interactive Pattern” bespoke to our needs. To achieve this, we need to reframe AI output as software-generated output. And, like anything related to software, we need to QA and think in terms of QA processes.
For instance, if we’re researching an article and AI provides us with some statistics, we should verify the primary sources for these statistics, just as a responsible reporter would. This pattern might look something like this:
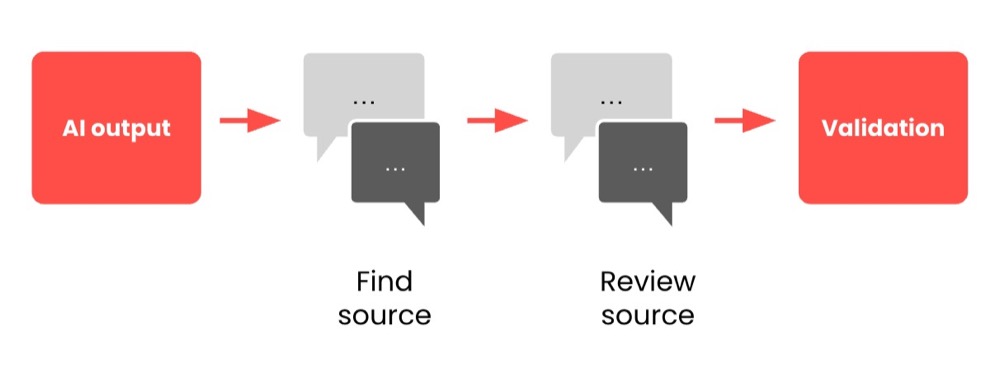
Each statistic is fed into a suitable LLM (e.g., Perplexity), with a prompt asking it to locate the relevant primary source. That source is reviewed, and if the primary source is validated, then we can establish accuracy.
Another example: If we’re asking AI to categorise user feedback, we can ask AI for a specific quote for us to cross-check against the raw data. See below:
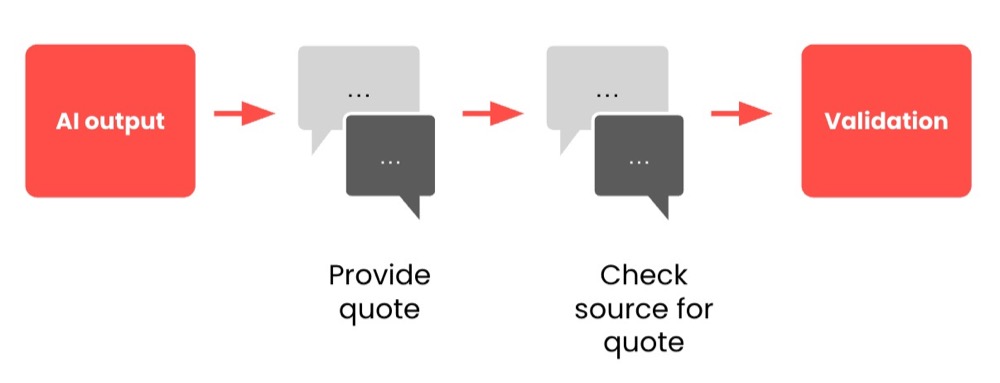
The validation pattern can be a separate AI agent, or it could be a human specialist with expertise in a particular field (this is often referred to as “human-in-the-loop”).
What’s important is that there is a clearly defined process or protocol to follow. The specific validation methods may vary depending on the requirements and dataset. We can even use AI to assist in developing tailored validation interaction patterns that meet our particular needs.
Hack 2: Optimised Prompting and Input
Even if we’re not building automated AI workflows, it’s likely we’ll be repeating the same tasks with AI again and again. Especially if we’re using AI for work. Investing time and effort to optimise our prompts can dramatically reduce hallucination rates.
This doesn’t mean maintaining a library of prompts to reuse—I’d advise against this, as it leads to over-reliance on copying and pasting and can result in complacency. Instead, focus on understanding how AI attention mechanisms work and learn how to manipulate them. For more details on this, read my article on examples and the power of AI attention.
Improving our prompts can also help reduce human biases that might otherwise creep into our interactions with AI systems.
Hack 3: Self-consistency checking
As we focus on improving our prompts, we’ll inevitably notice inconsistencies in AI outputs. While better prompt structure can reduce some issues, hallucinations may still appear even with well-crafted prompts.
This is where self-consistency checking becomes valuable. Newer “reasoning” LLM models use this technique internally. The method involves generating multiple possible answers and selecting the most consistent one. We can apply this same principle in our workflows and interactions, and it could look something like this:
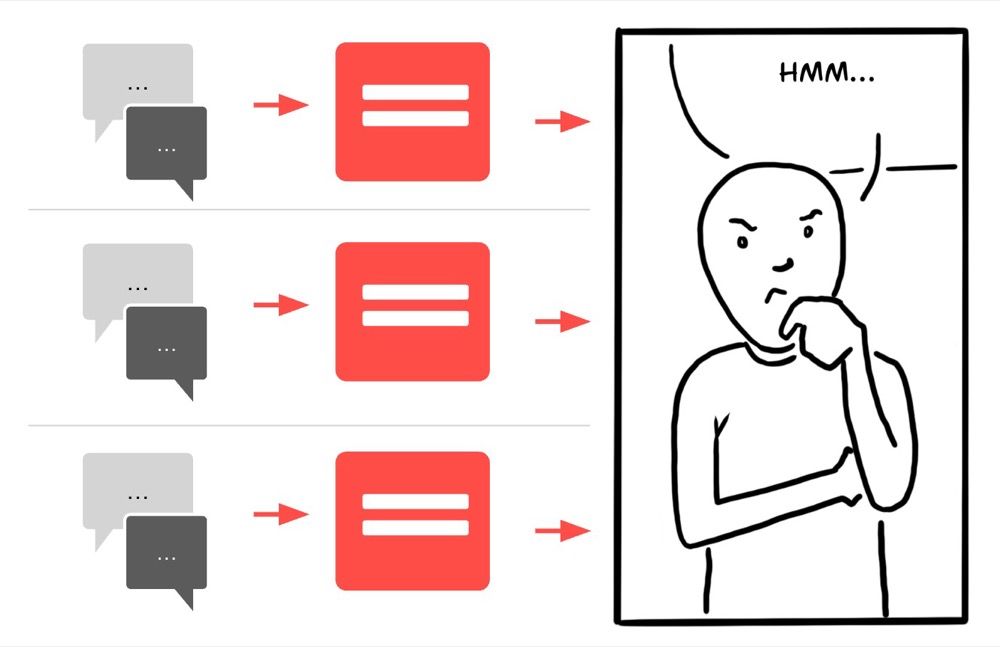
The technique is straightforward: Run identical prompts multiple times through the same model, or better yet, across different models. The variations in responses may reveal hallucinations. In theory, fabricated information shouldn’t appear consistently across multiple runs, so we should be able to identify hallucinations. Also, where multiple responses converge, that content is likely to be more reliable.
We can even collect all of the outputs and use the LLM itself to analyse for inconsistencies.

Here’s a prompt example:
Prompt: Compare these responses and identify any contradictions or inconsistencies between them. Which information appears most reliable based on consistency?
Tools like Open-WebUI streamline this process by allowing us to run identical prompts across multiple LLM models simultaneously, providing an immediate visual comparison of the responses from different models to the same query.
Hack 4: Use AI to validate biases
So far, we’ve mostly looked at controlling hallucinations from AI systems. But let’s not forget about the human element in our AI interactions. We can also define a specific interaction pattern that highlights our own biases.
After completing an important series of exchanges with AI, we can ask AI to highlight potential biases and critique our interactions. An example prompt might look like this:
Prompt: Review and critique our interaction. Highlight any biases in my inputs to you. For example, confirmation biases, leading questions, or any other patterns that might have influenced your responses.
This simple technique can often lead to significant improvements in AI interaction workflows. Over time, this approach will reveal patterns in your interactions with AI and highlight any potential biases that may exist. This will, in turn, help you become better at prompting and at crafting more objective prompts.
Conclusion
The consequences of AI hallucinations can be significant. They undermine trust, compromise decision-making, and can ultimately damage brands. As we increasingly use AI and as AI agents become more integrated into critical business operations, even slight inaccuracies can cause major problems.
The solution is to understand AI hallucinations, how and why they happen, and the various types of errors they are composed of. Only then can we create effective strategies to combat hallucinations. AI systems should be transparent, complex workflows should be broken down into smaller, manageable chunks, and we should develop processes to validate accuracy.
AI hallucinations are unlikely to disappear soon, but as long as we have thoughtful safeguards in place, we can mitigate the risks.


Written By
Iqbal Ali
Edited By
Carmen Apostu
