Local LLMs Part 2: How I Defeated ChatGPT 5 with the Smallest Language Model I Could Find
In part 1 of this series, we had a look at LM Studio and explored small models. I found a really good model, Qwen 3, which had 1.7 billion parameters.
It performed well, comparable to models of about one to two gigs in size. However, there was a promising model, the 0.6 billion parameter model, that I said I would come back to.
That model was tiny. It was less than 500 megabytes. So, it fits very easily within the RAM that I have and runs blazingly fast.
In this article, I’d like to review techniques for working with smaller models and explore ways to improve the behaviour of the 0.6 billion parameter model.
Recap of Our Task
We wanted to analyse some user feedback for insights, using this particularly gnarly example:
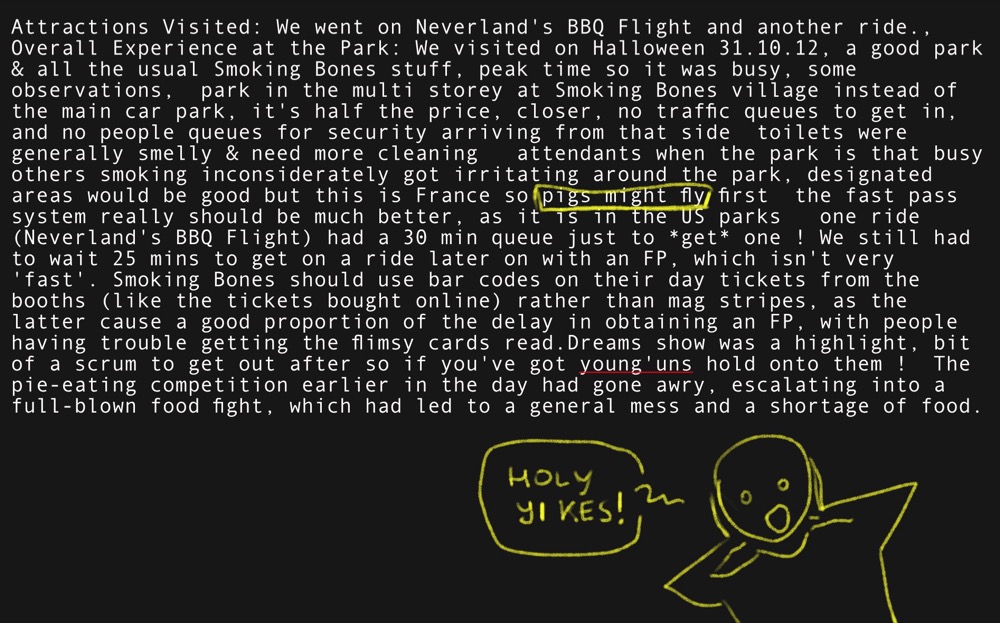
This included a colloquialism about pigs flying. We wanted to see if the models would avoid taking that literally.
We fashioned some “perfect” output with the help of AI, five specific insights that we think are important to capture:
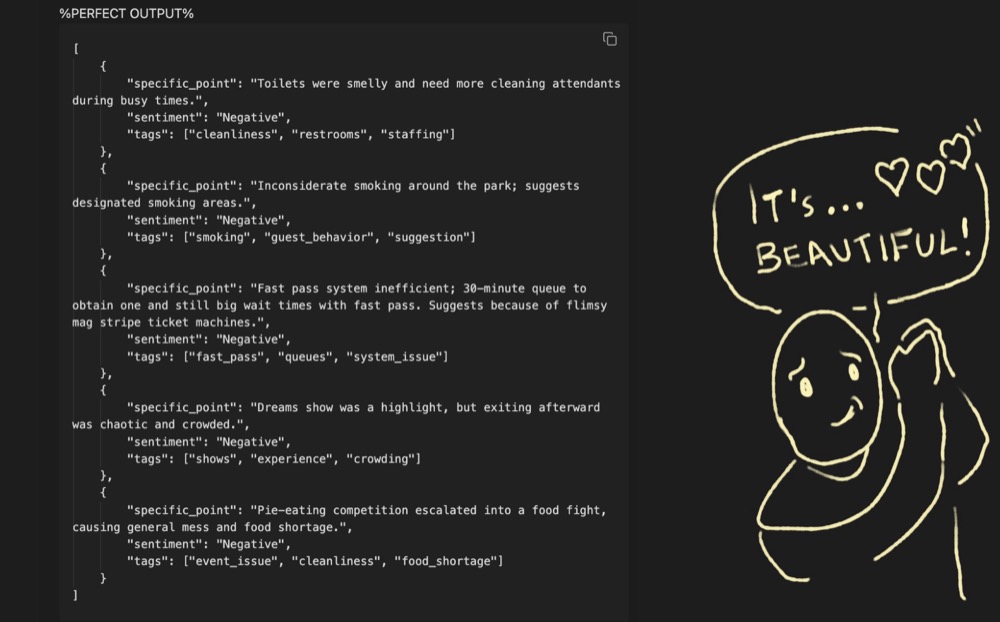
And ChatGPT performed okay.
It got more insights, but it was capturing things I didn’t really want. The 1.7 billion parameter model also captured around the same number as ChatGPT. So while neither of them were particularly bad, they weren’t perfect.
What Are We Trying to Do Now?
We want to see how we can utilise some prompting techniques to persuade the 0.6 billion parameter model to get closer to perfection.
In the previous test, we used a one-shot prompt, which means we had one user input and one specific example output.
Now, let’s copy this prompt into our 0.6 billion parameter model and play with the settings & prompts.
Trying Out the Temperature Settings
Temperature controls how much randomness to introduce to the LLM. Zero will give you the same result every time. Higher values will increase creativity and variance.
In my test, even at temperature = 1, the model consistently gave me two insights – good ones, but too few.
Trying Out a Few-Shot Prompt
The issue might be that I’m providing an example with two specific points as the one-shot example. Perhaps the 0.6 billion parameter model is overly focused on that aspect, potentially overlooking many other valuable insights? Let’s find out.
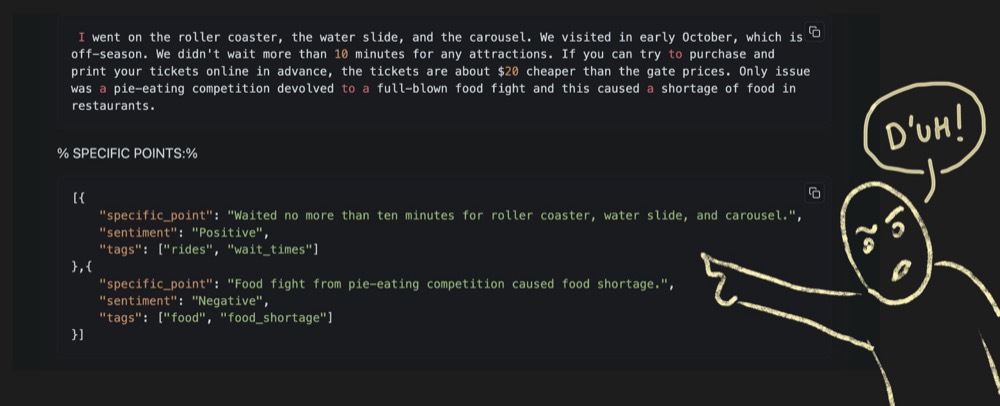
We’ll try a few-shot prompt, so instead of just one example (where I have two specific insights), let’s provide more examples with a more varied number of insights.
Here’s my new prompt (warning: it’s a long ‘un):
% CONTEXT:%
Smoking Bones Land is a series of BBQ-themed theme parks. There are rides, shows, and they have a cinematic universe. There are three locations: France, Hong Kong, and California.
%YOUR ROLE%
You are a customer service support analyst. Your aim is to identify specific problems that users are facing, so that you can improve the product and service. Ignore everything else.
% YOUR TASK:%
Identify only the specific points that are useful to a developer, product owner and support analyst. output in JSON format as defined.
% USER INPUT:
```
I went on the roller coaster, the water slide, and the carousel. We visited in early October, which is off-season. We didn't wait more than 10 minutes for any attractions. If you can try to purchase and print your tickets online in advance, the tickets are about $20 cheaper than the gate prices. Only issue was a pie-eating competition devolved to a full-blown food fight and this caused a shortage of food in restaurants.
```
% SPECIFIC POINTS:%
```json
[{
"specific_point": "Waited no more than ten minutes for roller coaster, water slide, and carousel.",
"sentiment": "Positive",
"tags": ["rides", "wait_times"]
},{
"specific_point": "Food fight from pie-eating competition caused food shortage.",
"sentiment": "Negative",
"tags": ["food", "food_shortage"]
}]
```
% USER INPUT:
Attractions Visited: I went on the roller coaster and the carousel., Overall Experience at the Park: What a wonderful place to come and forget all about the world and just concentrate on having fun! The rides are great. Just plan your day so you can make the most of fast passes etc. The food is extortionate so if you can bring a picnic do, or if you're staying at a Smoking Bones Land hotel get the meal package deal. The park opens 2 hours earlier for hotel guests but only a few rides are open. Still it's great to wander around before the madness starts! If you've never been ..... come... it's magical! The previous day's pie-eating competition had ended in a food fight, which left the park somewhat messy.
% SPECIFIC POINTS:%
```
[{
"specific_point": "Fast passes recommended to plan the day efficiently.",
"sentiment": "Neutral",
"tags": ["planning", "fast_pass"]
},{
"specific_point": "Food is very expensive; picnic or meal package deal suggested.",
"sentiment": "Negative",
"tags": ["food", "pricing"]
},{
"specific_point": "Park opens 2 hours early for hotel guests, but only a few rides are open.",
"sentiment": "Negative",
"tags": ["hotel_guests", "early_access"]
},{
"specific_point": "Previous day's pie-eating competition caused a food fight, leaving park messy.",
"sentiment": "Negative",
"tags": ["cleanliness", "event_issue"]
}]
```
%USER INPUT%
California park in early July was packed. Loved the new BBQ river ride—super immersive! But the queues for food were ridiculous, especially around the burger stand. Some kids areas were crowded and lacked shade. Consider adding more benches for waiting parents.
%SPECIFIC POINTS%
```
[
{
"specific_point": "California park was very crowded in early July.",
"sentiment": "Negative",
"tags": ["crowding", "capacity"]
},
{
"specific_point": "New BBQ river ride was immersive and enjoyable.",
"sentiment": "Positive",
"tags": ["new_ride", "experience"]
},
{
"specific_point": "Queues for food were very long, especially at the burger stand.",
"sentiment": "Negative",
"tags": ["food", "wait_times", "queues"]
},
{
"specific_point": "Kids areas were crowded and lacked shade.",
"sentiment": "Negative",
"tags": ["kids_areas", "crowding", "amenities"]
},
{
"specific_point": "Suggests adding more benches for waiting parents in kids areas.",
"sentiment": "Neutral",
"tags": ["suggestion", "amenities", "seating"]
}
]
```
%USER INPUT%
```
Attractions Visited: We went on Neverland's BBQ Flight and another ride., Overall Experience at the Park: We visited on Halloween 31.10.12, a good park & all the usual Smoking Bones stuff, peak time so it was busy, some observations, park in the multi storey at Smoking Bones village instead of the main car park, it's half the price, closer, no traffic queues to get in, and no people queues for security arriving from that side toilets were generally smelly & need more cleaning attendants when the park is that busy others smoking inconsiderately got irritating around the park, designated areas would be good but this is France so pigs might fly first the fast pass system really should be much better, as it is in the US parks one ride (Neverland's BBQ Flight) had a 30 min queue just to *get* one ! We still had to wait 25 mins to get on a ride later on with an FP, which isn't very 'fast'. Smoking Bones should use bar codes on their day tickets from the booths (like the tickets bought online) rather than mag stripes, as the latter cause a good proportion of the delay in obtaining an FP, with people having trouble getting the flimsy cards read.Dreams show was a highlight, bit of a scrum to get out after so if you've got young'uns hold onto them ! The pie-eating competition earlier in the day had gone awry, escalating into a full-blown food fight, which had led to a general mess and a shortage of food.
% SPECIFIC POINTS:%
```
All I’m doing differently is I’ve got two more user input and output pairings as examples to use with this 0.6 billion parameter model.
Trying that out, I got: three insights, then two, then three. A little better, but it also got caught up in that colloquialism about pigs flying. After testing 10+ times, the results overall were not great but still promising.
But what can we do to get even better results?
Introducing “Breakpoints”
Now, bear with me a little bit. We’re about to get a bit technical, but only a little.
What we have below is a simple JavaScript function. A = 5, B = 10. The result of A + B is 15. So, if I run this, I get 15, which is all great.
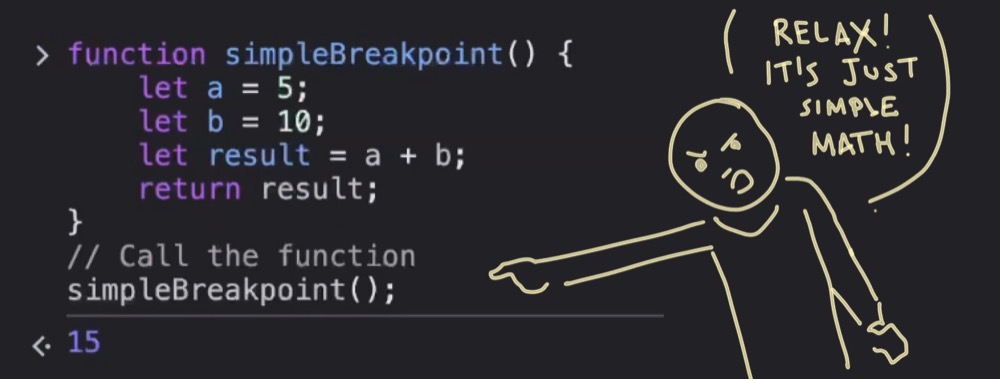
Now imagine this code was much more complicated and somewhere along the way we had +1 added to the value of B. Instead of 15, we now get a result of 16. This is not what we intended. But how do we figure out where this function is going wrong?

I want to introduce you to the concept of breakpoints. A breakpoint is a technique in development where we insert a pause or “break” in the running of some piece of code, so we can take a look around and view the state of the application at that given point in time.
So, imagine we were to enter a breakpoint here:

Note: I used “debugger” in this example for clarity, but I could have just easily used a marker instead:

The code pauses as soon as it gets to the debugger, and we can evaluate the values of the variables.

At this point, A = 5, B = 10, everything’s working fine. But then, if we add another debugger after ‘b+1’ and run it, we see that our variable B = 11. Using these breakpoints, we’re able to pinpoint exact locations of defects.
Applying the Breakpoints Concept to Prompting
Now, why am I telling you all of this? We can think of an LLM as a very complex piece of code. We prompt in, we get something out, and we have no idea what’s going on inside. It’s a black box. And we need to insert a breakpoint somehow.
But how do we do that if we don’t have control of the LLM’s code base? We have control over the prompts we use, and so we can simulate breakpoints by breaking down our prompts.
We’ve got our user input, which is really messy. We may be asking too much from this little model. Not only are we asking it to find the insights, but we are also asking it to structure the output as JSON as well.
To help identify a breakpoint, we can review the reasoning process of the model and see what steps the model takes:
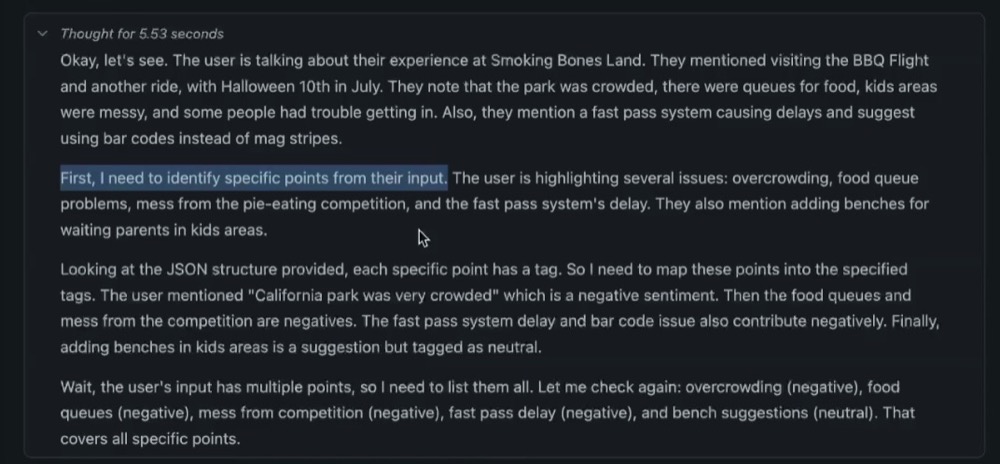
As suspected, the first step is to identify the specific points from the input. So, here’s what we can try as our interaction:

We split our original prompt into two. The first prompt is where I just get the LLM to summarise the insights and not worry too much about the structure.
Here’s my updated prompt:
% CONTEXT:% Smoking Bones Land is a series of BBQ-themed theme parks. There are rides, shows, and they have a cinematic universe. There are three locations: France, Hong Kong, and California. %YOUR ROLE% You are a customer service support analyst. Your aim is to identify specific problems that users are facing, so that you can improve the product and service. Ignore everything else. % YOUR TASK:% Summarise, focusing on the insights that are useful to a developer, product owner and support analyst. Write as a list, with a reason why it's useful and what it means in the context of the question asked. Only list where there is good reasoning. % USER INPUT:% ``` I went on the roller coaster, the water slide, and the carousel. We visited in early October, which is off-season. We didn't wait more than 10 minutes for any attractions. If you can try to purchase and print your tickets online in advance, the tickets are about $20 cheaper than the gate prices. Only issue was a pie-eating competition devolved to a full-blown food fight and this caused a shortage of food in restaurants. ``` %SUMMARY% ``` - We didn't wait more than 10 minutes for any attractions. - short wait times indicate no problems - Only issue was a pie-eating competition devolved to a full-blown food fight and this caused a shortage of food in restaurants. - Problem with pie eating contests The following user input %USER INPUT% ```Attractions Visited: We went on Neverland's BBQ Flight and another ride., Overall Experience at the Park: We visited on Halloween 31.10.12, a good park & all the usual Smoking Bones stuff, peak time so it was busy, some observations, park in the multi storey at Smoking Bones village instead of the main car park, it's half the price, closer, no traffic queues to get in, and no people queues for security arriving from that side toilets were generally smelly & need more cleaning attendants when the park is that busy others smoking inconsiderately got irritating around the park, designated areas would be good but this is France so pigs might fly first the fast pass system really should be much better, as it is in the US parks one ride (Neverland's BBQ Flight) had a 30 min queue just to _get_ one ! We still had to wait 25 mins to get on a ride later on with an FP, which isn't very 'fast'. Smoking Bones should use bar codes on their day tickets from the booths (like the tickets bought online) rather than mag stripes, as the latter cause a good proportion of the delay in obtaining an FP, with people having trouble getting the flimsy cards read.Dreams show was a highlight, bit of a scrum to get out after so if you've got young'uns hold onto them ! The pie-eating competition earlier in the day had gone awry, escalating into a full-blown food fight, which had led to a general mess and a shortage of food. % SUMMARY:% ```
The second prompt involves taking the output from the previous part and structuring it.
Prompt:
Give me the output as structured JSON in this format:
[{
"specific_point": "[summary of the specific insight]",
"sentiment": "[Positive|Negative|Neutral]",
"tags": ["tag1", "tag2"]
},{ .. }
After trying a few times, no joy. Not worth showing you a screenshot since there’s nothing new to see.
So how else could we break this down? Well, we’re asking the model to find insights across a range of sentiments, including positive, negative, and neutral.

What if we made this even easier and broke our prompts down according by sentiment? Our first prompt could focus on the negative insights:
Prompt:
<As before> % YOUR TASK:% List the negative insights mentioned in the user feedback below, that is specific to the context, ignoring colloquialisms. Write insights as a list, with a reason why it’s useful and what it means in the context of hte question asked. <...as before>
And the results are much better! Five and it’s found all of the right insights.

Testing again, it found seven, with insights on par with ChatGPT. It’s also not picking up on that colloquialism, but I had to prompt it specifically.
Here’s my final interaction pattern:

Those ChatGPT shit heads are the size of a planet, while this thing is the size of a pea, and I’m able to get the same performance out of it for my use case. Albeit with three prompts instead of one, but it’s blindingly fast on a local machine.
What’s Next?
Now, the job’s not finished yet. I need to test this extensively and find a way to automate the interaction pattern. I also have training in mind for this thing.
But I hope this has proven the power of small local models. I also hope this spurs you on to give these kinds of models a chance with your specific tasks, applying techniques like this to see how you can get the best out of them.
Editor’s note: This is part of our series on running AI locally. If you want to keep going, check out how to set up a local LLM server with LM Studio and Ollama and build your own personal chat interface.


Written By
Iqbal Ali
Edited By
Carmen Apostu
