Context Windows, Structured Data, and the Fundamentals of Text Analysis with AI
Are you using AI to analyse customer feedback, surveys, or other forms of unstructured text data? If so, then you’ve likely already faced the limitations of “context windows”, whether you know it or not. These hidden constraints undermine the accuracy and validity of your insights, especially when dealing with insights like this:

In this article, I’ll share the practical strategies I’ve developed over years of working with AI for user research and product development. You’ll learn techniques and strategies to work around context window limitations to get the most out of your LLM interactions and unlock the true value of your data.
Disclosure: I am the developer of Ressada, a user research tool that implements many of the techniques discussed in this article. However, this article focuses on general approaches that can be applied to any AI system.
What’s the problem anyway?
According to Gartner, approximately 80% of enterprise data is unstructured (Gartner, “Market Guide for File Analysis Software”, 2019). In addition, the following white paper by the International Data Corporation (IDC) states that just over 50% of that data is underutilised. That’s a lot of insights left on the table.
But, wait. The solution is simple, right? We can just use the “blah blah” prompt we picked up from our nearest LinkedIn feed…

…stuff it into our chat tool of choice with all our data. And presto, we got ourselves some insights.
I mean, there’s no point worrying about limitations with context windows this large, right?

Unfortunately, the real picture is not quite so simple.
What are context windows?
Let’s start with a definition of context windows. When we prompt the AI, that prompt is broken into pieces called tokens. A token can be an individual word or even punctuation. Different models break down the text to tokens in various ways. To simplify things, we’ll just count words to approximate tokens and context window sizes.

Note: This is a gross simplification of how LLMs work. For more details, read my other articles on the subject. Or don’t, because this is all you need to know for the rest of this article.
A context window is the size of our prompt, the chat history, and the output, measured in tokens.
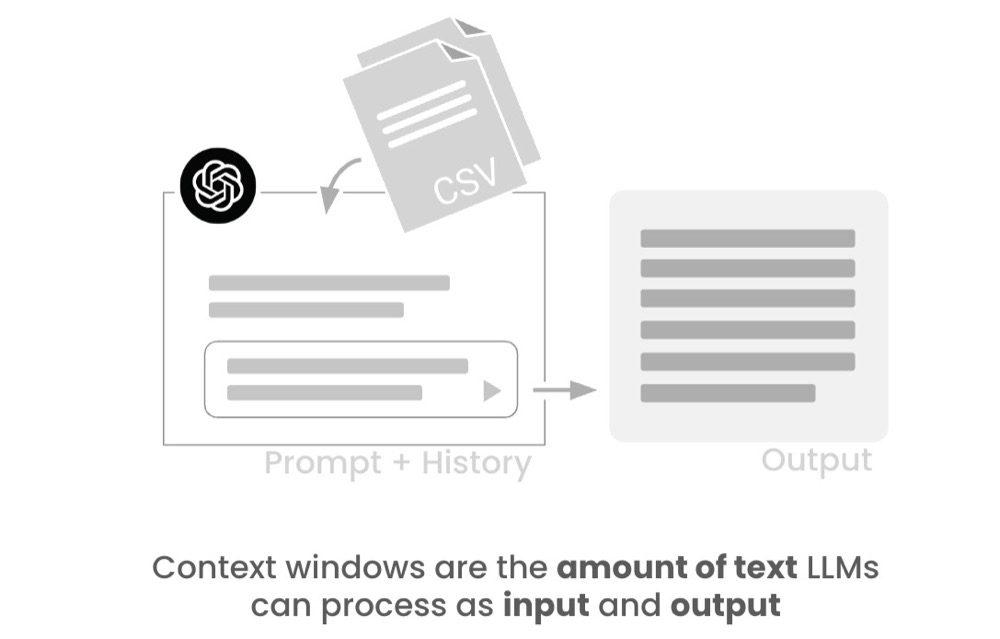
Previous models had limited context windows. More recent AI models have substantially increased these limits. Check out the context window sizes below!
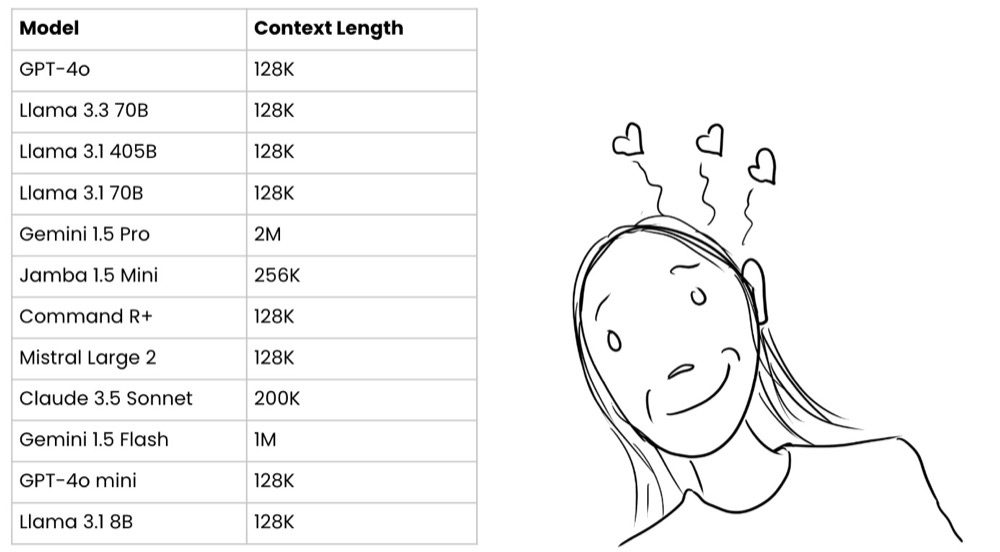
Specifically, check out those Gemini models!
Gemini 1.5 Pro: 2M Gemini 1.5 Flash: 1M
Amazing, right? For reference, 1 million tokens is approximately the length of the first 6 Harry Potter books.

But let’s explore this a little further.
Literal matching vs latent matching
LLM models use the context of our prompts to build a sort of associations map. They then choose the “best” associations based on our prompt text:
This is an extreme simplification of the actual process. If you want to learn more about this, you can check out my previous article on this. Needless to say, the LLM finding the most relevant associations is a key factor for accuracy.
This brings us to the study “NoLiMa: Long-Context Evaluation Beyond Literal Matching“, which defines two types of matching.
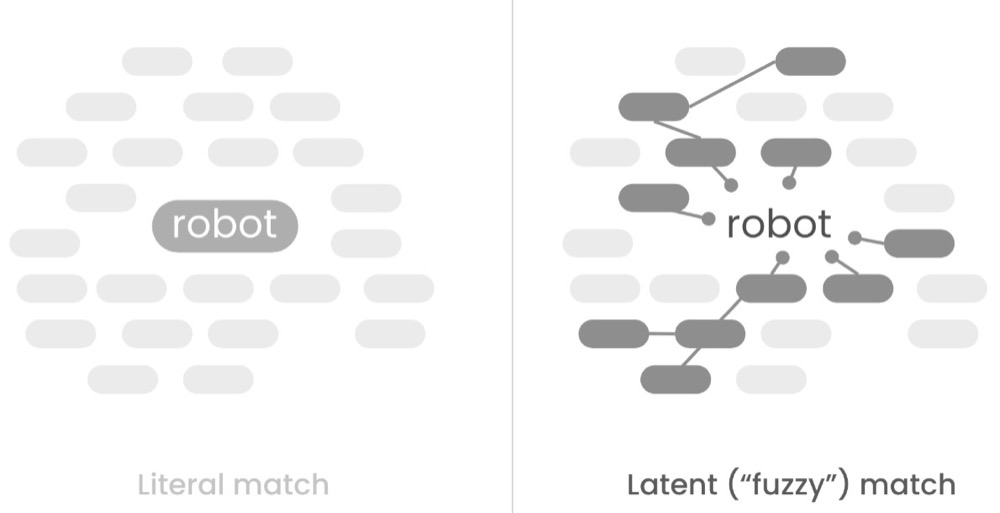
Literal matching is where the LLM finds associations that are either identical matches or highly similar words or phrases to the prompt. So, for example, if we have a dataset of customer feedback and we prompt “What do customers think of our checkout flow?”, a literal match would locate feedback that mentioned “checkout”.
Latent matching, on the other hand, finds associations that are conceptually similar to the words in the prompt. So, for the prompt “What do customers think of our checkout flow?”, a latent match would locate feedback that mentioned “payment flow,” “finalising purchase,” or “completing my order”, because they are conceptually similar to the prompt.
Now, refer back to those previous context window performance numbers. These numbers are based on literal matches.
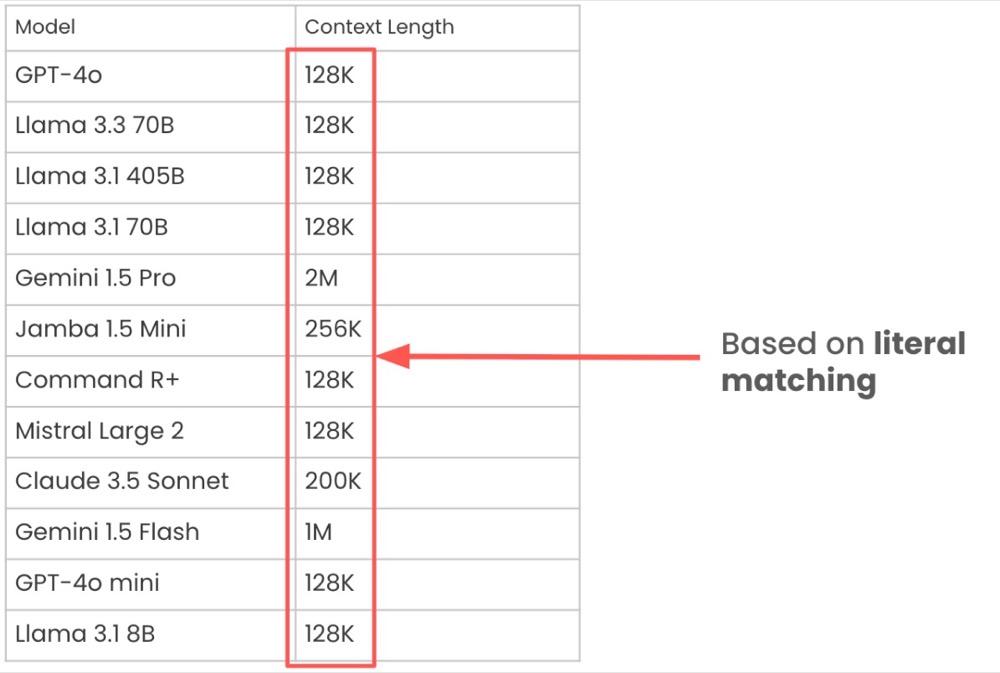
When we compare the performance of latent matching vs literal matching, an entirely different picture emerges.
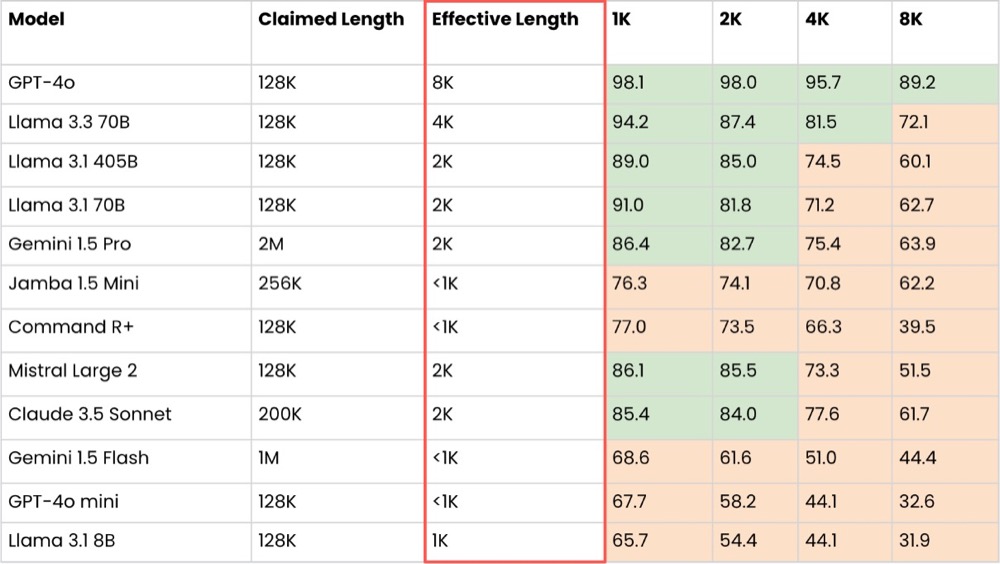
As you can see from the above, the effective match of latent matching (where the accuracy of given tasks is 80% or higher) is less than the claimed length.
Gemini 1.5 Pro: 2M? More like 2k. Gemini 1.5 Flash: 1M? More like less than 1k.
Now, admittedly, this is a gross simplification of the NoLima paper’s findings. In truth, there’s a pattern to degradation that differs according to the model. According to their findings, here is a brief summary by model:
GPT-4 tends to recall information better near the beginning and end of the context window and may struggle with mid-context information in very long contexts.
Claude (Anthropic) generally shows more uniform attention across its context window, so it performs better when retrieving information from the middle of long contexts. It also has a relatively stable performance up to 60k tokens.
Gemini (Google) shows different patterns depending on the specific model version, but generally gracefully degrades context. I’ll admit, Gemini 1.5 Pro shows impressive reasoning across long contexts.
For a more nuanced and detailed view, I recommend reading their paper.
The main point is this: When we’re dealing with unstructured text generated by users in forms, emails, etc., it’s safe to assume that users are not going to use consistent language and terminology, so the literal match performance is perhaps more realistically what we can expect.
We also need to consider how each model degrades when handling larger context sizes, and pick the one that best suits our data needs.
Alternatively, if we manage our context window sizes better, we can become model-agnostic and greatly simplify things. So, with that said, let’s look at ways of managing context windows, going from simple to progressively more advanced techniques.
Managing context windows: simple techniques
We’ll start with the easy wins related to the chat interfaces themselves.
Technique 1: Start a new conversation or thread
A simple tip is to avoid doing everything in the same chat thread. Get into the habit of creating new conversation threads, as this resets your context window.
Technique 2: Re-edit earlier prompts
Review any chat threads and you’ll notice a little pencil icon below each prompt. This allows us to edit that prompt. If we edit an earlier prompt, only the context window up to that point is used. When we do this, we’re effectively creating an alternate timeline for the conversation.
Technique 3: Summarise the current conversation
Sometimes editing or starting a new conversation isn’t an option. The context of previous conversation threads may be useful to keep. If that’s the case, summarising the conversation may be a way forward.
A good summary of a conversation thread is one that retains the key points important to your task flow. Therefore, a structured summary can be useful. I’ve had success with a prompt that asks for the following:
- One sentence summary of the conversation
- The main goal of the conversation
- List of key pieces of information
Having the content and structure like the one above allows for easier scanning. It also ensures we don’t lose too much information from our conversation thread. When reviewing the summary, if we find anything missing, we can add it manually.
This summary can then be used in new conversations as context.
Managing context windows: advanced techniques
The above techniques are a good start, but we can do much more here. I mentioned in an earlier article that I consider using AI for research to be essentially an Information Architecture problem.
Information Architecture is the application of structured design and organisation to information to make it easily understandable, accessible, and usable.
Consider a library stocked with books. Now imagine using a library that doesn’t sort books alphabetically, or by genre, or by anything else. Imagine how difficult it would be to find the right book? Thankfully, libraries don’t operate in that way. Books are sorted and categorised. There’s an inherent structure to the data a library stores.
Before we seek, we need to apply some structure. In other words:

The concept is simple. We have our unstructured text that we want to mine for insights. Before we start mining for insights (i.e. seeking), it’s a good strategy to structure our data first. This allows us to reap the benefits of structured data, like filtering text to use only relevant data.
An added benefit of filtering the data beforehand is that, since the context is more relevant, the LLM output is more accurate because the LLM has fewer distractions in the context.
Here’s how to go about structuring data…
Technique 4: Tag and structure data
Let’s use a simple example. Imagine we own a series of theme parks. We conduct a simple feedback survey and collect the following information:
- Branch (which of my three theme park branches did you visit?)
- Month (which month did you visit my theme park?)
- Free text (open text to provide your feedback)
Once responses are collected, the spreadsheet will look like this:
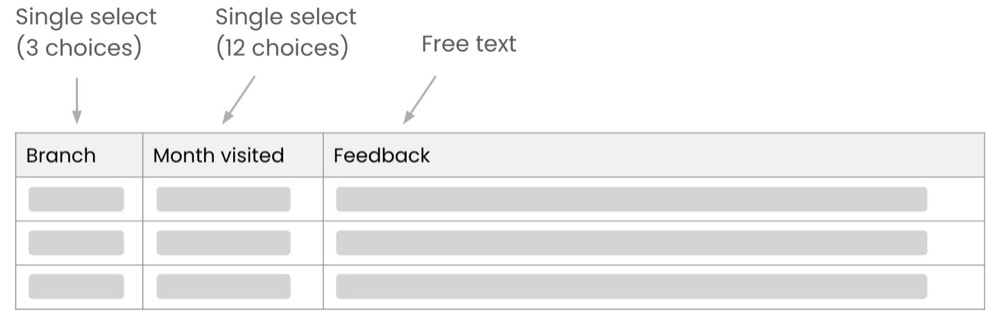
Two of those columns already have a good structure—the first two are single-select fields, thus allowing us to filter by specific branch or month visited. Now we want to add structure to that open feedback text so we can filter it in a similar way. We’ll do this by adding extra columns that “describe” the text in ways that are useful to us.

These additional columns can be sentiment, category labels, freeform tags, or anything else that’s valuable for us. Our additional column requirements might differ according to our needs.
When doing this, it’s important to ensure the language used in each column is consistent, so it can be used as a filter. A simple prompt to do this could be like the following:
Prompt: I’m a user researcher working for Smoking Bones Land. Parks which has rides and attractions with a BBQ theme. Here is a table of feedback from users.
Create additional columns for “theme labels” and “general sentiment”.
Feedback: <feedback text>
Since we’re tagging multiple responses at the same time, the language will be consistent.
If we need to process another batch of responses or each response individually, we need to feed the labels created in previous rounds into the AI so we can “normalise” them and ensure consistency of labelling.
Prompt: I’m a user researcher working for Smoking Bones Land. Parks which has rides and attractions with a BBQ theme. Here is a table of feedback from users.
Create additional columns for “theme labels” and “general sentiment”.
Theme labels: Here are some labels you generated earlier. Apply these if relevant: <previous labels>
Sentiment: Positive, Negative, Neutral
Feedback: <feedback text>
We can store the resulting output in a spreadsheet or database. And now, when we look for user problems in the dataset, we can filter feedback accordingly. For instance, we can use negative feedback to find user pain points and frictions.
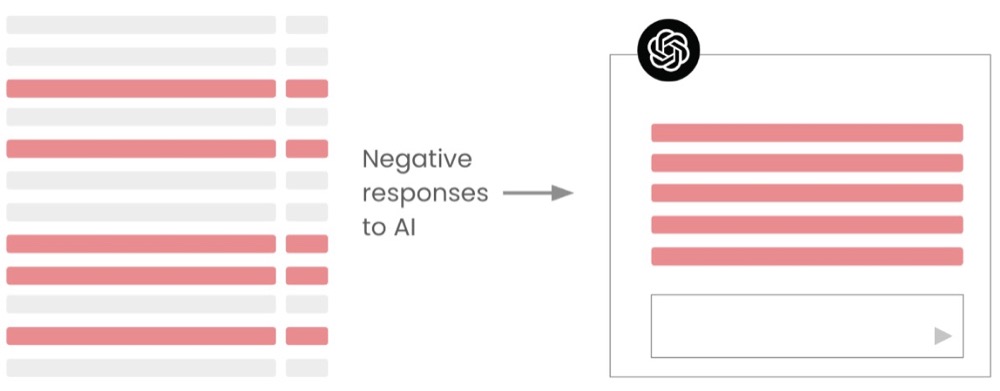
Doing this not only reduces our context window footprint but also improves our overall accuracy since we’re removing irrelevant data (in this case, the positive and neutral feedback are not used).
Additionally, since we’re tagging and labelling our data with consistent language, we can utilise the larger context window performance of the LLM, since we’re using the literal matching capabilities.

Note: We still might not get the best accuracy with a 2-million-token context window, but at least we’re doing our best with what we have.
Technique 5: Progressive summarisation
We can go a step further with our structuring efforts by creating progressively summarised versions of the feedback text. We can also clean up the text as we summarise, which allows us to scan and review it more easily. To progressively summarise effectively, we need to iterate over each user response and create progressively shortened versions of the feedback text.
For instance, we can summarise in less than twenty words before more aggressively summarising in six to ten words.
When doing this, be sure that the summaries have the desired information density. Tip: Use some good examples to ‘tell’ the AI how to summarise (read my previous article for details). Also, give as much context as possible to ensure effective summarisation.
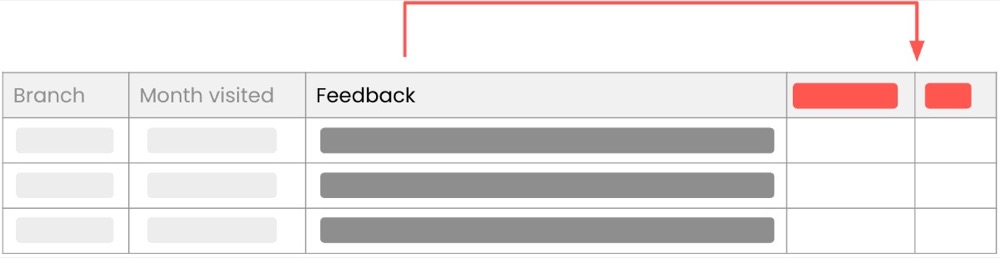
Having a choice of different levels of summaries gives us more control over the context windows when we’re seeking. Add some filtering to the mix, and we can do much within a decent-sized context window footprint.
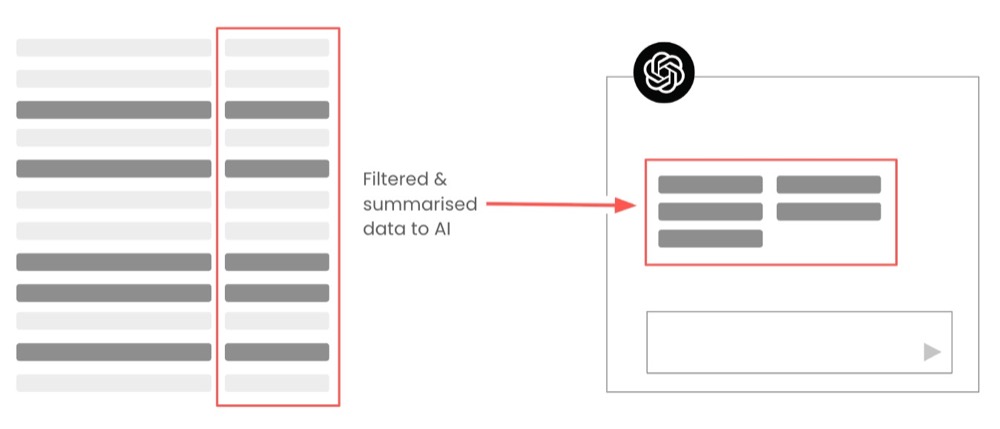
In my experience implementing these techniques in research software, they can effectively process tens of thousands of feedback items without significant accuracy degradation.
Technique 6: Recursive summarisation
We can also do recursive summarisation of our feedback, which means we create summaries of our summaries to further condense the word count, increasing its information density.
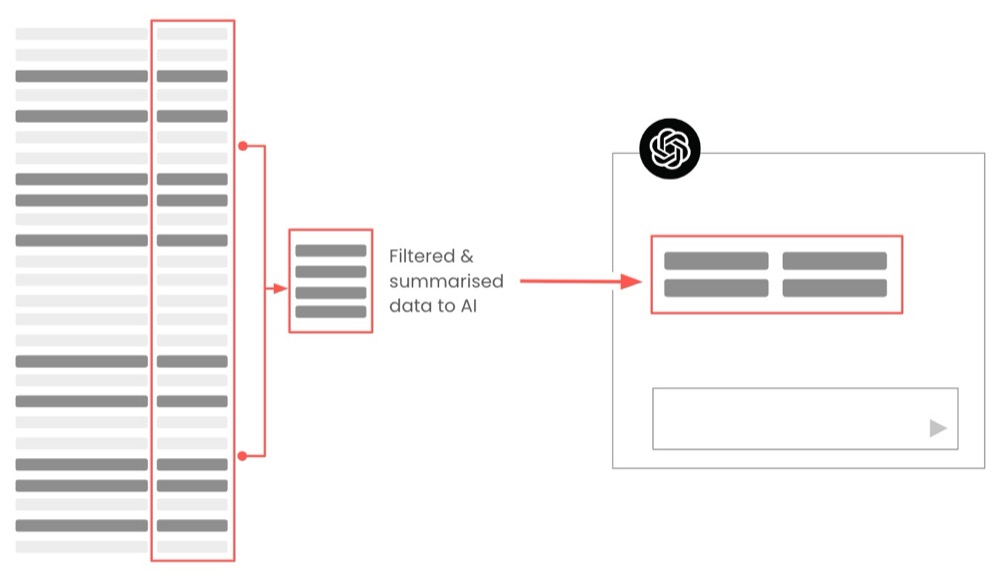
Recursive summaries are useful for a high-level view of our data, such as getting an overview of the kinds of problems users are facing. Since duplicate mentions across users will be summarised, we can’t rely on this kind of summary for specific details.
However, if we maintain a relationship between our recursive summaries (for instance, in a database), we can ask follow-up questions with progressively more detailed summaries.
Again, when creating recursive summaries, add plenty of context and use examples to direct the summarisation carefully.
Technique 7: Retrieval Augmented Generation
So far, we’ve done a lot manually, storing structured data in a spreadsheet. In a way, we’re acting as a retrieval engine for AI. If we are looking for the ultimate way of effectively managing our context window sizes, I consider RAG (Retrieval Augmented Generation) to be the Rolls-Royce of context window management.
This method replaces the spreadsheet with a vector database. A vector database breaks down text into embeddings (numerical representations of text) and allows us to retrieve data semantically based on the search query. For instance, if we asked our database: “What feedback do we have about our login process?”, a RAG system would search across all feedback for semantically relevant text about the login process.
The advantage of this approach is that it scales to a virtually unlimited amount of data while maintaining the same high relevance as the data scales. Additionally, we use a vector database that can handle relational data. In that case, we can also filter by sentiment, tag, or other useful criteria we’ve added, before doing the semantic query. This adds further efficiencies to our context window management.
RAG is a vast topic that is well beyond the scope of this article, but I include it for the sake of thoroughness. Also, I’ve found that adding more and more structure to our data kind of negates the need for RAG. There’s a lot we can do with a good data structure for our text feedback.
What’s next
Context windows are one aspect of LLMs that chip away at our data quality. When the AI hype train comes to town, it’s easy to overlook the importance of simple data structures and context window management. This doesn’t mean we all need to jump to RAG; it just means doing our due diligence and utilising the relevant techniques outlined above to get the most out of our text analysis.
Editor’s note: This guide is part of a broader series on building practical AI systems. For more on getting better results from language models, explore our guides on reducing hallucinations, using examples to lock in consistent output, and making the case for smaller models.
References
- Market Guide for File Analysis Software, Gartner, 2019
- What every executive needs to know about unstructured data, IDC, 2023
- NoLima: Long-context evaluation beyond literal matching, Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Trung Bui, Ryan Rossi, Seunghyun Yoon, Hinrich Schutze, 2025


Written By
Iqbal Ali
Edited By
Carmen Apostu
